
Large language models can generate impressive responses, but they can also produce confident answers that are wrong, unsupported, or misleading. This is known as an LLM hallucination and can reduce trust in real-world AI systems.
That is why LLM hallucination detection and faithfulness checks are becoming essential. Businesses using AI in chatbots, search, copilots, and automation need ways to verify that outputs are accurate and grounded in reliable sources.
In this guide, I’ll explain how to detect hallucinations, measure faithfulness, and improve LLM output quality.
What are LLM Hallucinations?
LLM hallucinations happen when a large language model generates information that sounds believable but is false, unsupported, or not grounded in the provided source. The response may appear confident and well-written, making errors harder to spot.
These hallucinations can include made-up facts, incorrect citations, wrong calculations, or answers that drift from the original context. Detecting LLM hallucinations is important for building trustworthy AI systems, especially in healthcare, finance, legal, and customer-facing use cases.
What is Faithfulness in LLM?
Faithfulness in LLM refers to how accurately a model’s response stays aligned with the information, context, or source it was given. A faithful answer does not invent facts, distort meaning, or add unsupported details.
In simple terms, if the model receives correct source material, the output should reflect that source truthfully and clearly. Faithfulness is especially important in RAG systems, document Q&A, customer support, and any workflow where answers must remain grounded in provided data.
2 Types of Hallucinations in LLMs
- Factuality Hallucinations
- Faithfulness Hallucinations
What are Factuality Hallucinations in LLM?
Factuality hallucination happens when the LLM model gives information that sounds true but is factually wrong. For example, you ask questions like “Who is the president of India in 2024?”, the model replies “Amit Shah is the president of India.”
The sentence sounds correct, but it's factually wrong. The real president is Droupadi Murmu in 2024. This is a factual hallucination. These kinds of mistakes are risky, especially in areas like news, education, and healthcare. That’s why checking for factual accuracy is very important when using AI.
Two kinds of Factuality Hallucinations
Factual Inconsistency
Factual Inconsistency means the model gives answers that don't match the facts in the original information. It may change, add, or remove important details. For example, you ask the model, “When was the COVID-19 vaccine first rolled out?”, and if LLM replies, “The COVID-19 vaccine was first rolled out in 2021.”This is a factual inconsistency because the actual year is 2020, but it changed the year.
Factual Fabrication
Factual Inconsistency means the model makes up information that is not in the original source and is not true. It creates facts that were never mentioned.
For example, if the source says, “Unicorns are mythical creatures often described as white horses with a single horn on their forehead" and you ask the model, "Where do unicorns live" but it replies, "Unicorns live in the forests of Scotland and are often seen by travelers" this is factual fabrication.
The model added a fake detail (about unicorn lives but its methodology character) that was not in the original text. This kind of error is risky because the answer sounds real but is actually made up.
What are Faithfulness Hallucinations in LLM?
Faithfulness Hallucinations happen when the model doesn’t stick to the input or instruction.
Three kinds of faithfulness hallucinations
- Instruction Inconsistency → The model ignores the user's instructions.
Example: Instruction: “Translate this question to Spanish.” The model gives the answer in English instead.
- Context Inconsistency → The model says something that doesn’t match the provided information.
Example:If the context says, “Ananya Sharma was born in Chennai, India,” and the user asks, “Where was Ananya Sharma born?” but the model replies, “Ananya Sharma was born in Mumbai,” this is context inconsistency.
The model had the correct information, but gave an answer that contradicts it. Even though the question is simple and the answer sounds real, it doesn’t match the provided details, which makes it incorrect.
- Logical Inconsistency → The model starts right, but makes a logical or calculation mistake. Example: In a math problem, it begins solving correctly, but messes up the final step.

Walk away with actionable insights on AI adoption.
Limited seats available!
Why Do We Need To Evaluate Hallucinations And Faithfulness?
Evaluating hallucinations and faithfulness is essential because confident-sounding AI answers are often mistaken for correct ones. Large language models can generate false information, unsupported claims, or responses that change the meaning of the original source.
If left unchecked, these errors can create serious risks in areas like healthcare, law, finance, and education where accuracy matters most. By measuring hallucinations and faithfulness, teams can improve model reliability, build user trust, and create safer AI systems for real-world use.
How To Evaluate Hallucinations And Faithfulness In 7 Steps?
Human Evaluation – A person reads the LLM answer and checks if it’s correct and matches the source. This is the most accurate method.
Automatic Evaluation – Tools or models check if the LLM answer is supported by the source using techniques like:
- Similarity checks (comparing answer and source)
- Fact-checking models (detecting unsupported claims)
- NLI (Natural Language Inference) (seeing if the answer logically follows the source). Many teams host these checks in UI for LLM with Gradio.
Code
This code creates a simple web app where you upload a PDF and ask a question. It reads the PDF, finds the most relevant sentence, and gives a sample answer. Then, it uses DeepEval to check how good the answer is.
DeepEval tells if the answer has any made-up information (hallucination) or if it changes the meaning of the original text (faithfulness). It gives scores and reasons so you can understand how correct and reliable the answer is.
Step 1: Import Dependencies
import gradio as gr
from sentence_transformers import SentenceTransformer
import torch
import fitz
import os
from openai import OpenAI
from deepeval.metrics import HallucinationMetric, FaithfulnessMetric
from deepeval.test_case import LLMTestCase
from google.colab import userdata These libraries help us:
- These are evaluation metrics from the DeepEval library. They help check if a model’s output is hallucinated (made-up) or faithful (true to the source).
- Wraps the model’s input, output, and context into a test case that can be passed into evaluation metrics.
- Fitz from PyMuPDF helps read PDF files and extract text from them.
Step 2: Environment setup and loading the Sentence Embedding Model
# Set OpenAI key from Colab secrets
os.environ["OPENAI_API_KEY"] = userdata.get("OPEN_AI_API_KEY")
# Init OpenAI client
client = OpenAI()
model = SentenceTransformer('all-MiniLM-L6-v2')
It converts text (like questions or sentences) into numerical vectors for comparison.
Step 3: Initialize Evaluation Metrics
hallucination_metric = HallucinationMetric(threshold=0.5)
faithfulness_metric = FaithfulnessMetric()We create two metrics:
- hallucination_metric: Checks if the response contains any made-up facts.
- faithfulness_metric: Checks if the response follows the context properly.
Step 4: Extract Text from PDF Function
text = ""
for page in doc:
text += page.get_text()def extract_text_from_pdf(pdf_file):
doc = fitz.open(pdf_file.name) # FIX: open using file path
return textOpen the uploaded PDF file using its filename. Loop through all the pages in the PDF and collect all the text into one string. Then return the complete text.
Step 5: Get GPT response
def get_llm_response(context, question):
prompt = f"Context:\n{context}\n\nQuestion: {question}\nAnswer:"
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
return response.choices[0].message.content.strip()Suggested Reads- What are Temperature, Top_p, and Top_k in AI?
This function, get_llm_response, is used to ask a question to the LLM (like GPT-4o-mini) using a given context. It first creates a prompt by combining the context (a short part of the PDF related to the question) and the question itself.
Then it sends this prompt to the LLM using the new chat.completions.create method. The model reads the context, understands the question, and generates an answer. Finally, the function returns that answer as a clean string.
This function is helpful when you want the LLM to answer based on specific information, like from a PDF file.
Step 6: Main Logic for PDF QA and Evaluation
def process_pdf_and_question(pdf_file, question):
try:
text = extract_text_from_pdf(pdf_file)
reference_texts = [sent.strip() for sent in text.split(".") if sent.strip()]
if not reference_texts:
return "", "", "", "No text extracted from PDF.", ""
question_embedding = model.encode(question, convert_to_tensor=True)
best_score = -1.0
best_context = ""
for ref_text in reference_texts:
ref_embedding = model.encode(ref_text, convert_to_tensor=True)
similarity = torch.nn.functional.cosine_similarity(
question_embedding.unsqueeze(0), ref_embedding.unsqueeze(0)
).item()
if similarity > best_score:
best_score = similarity
best_context = ref_text
model_output = get_llm_response(best_context, question)
test_case = LLMTestCase(
input=question,
actual_output=model_output,
context=[best_context],
retrieval_context=[best_context]
)
hallucination_metric.measure(test_case)
faithfulness_metric.measure(test_case)
return (
question,
best_context,
model_output,
f"Hallucination Score: {hallucination_metric.score:.2f}\nReason: {hallucination_metric.reason}",
f"Faithfulness Score: {faithfulness_metric.score:.2f}\nReason: {faithfulness_metric.reason}"
)
except Exception as e:
return "", "", "", f"❌ Error: {str(e)}", ""
This function runs when a user uploads a PDF and asks a question. Extract all text from the PDF and then split it into sentences. This kind of preprocessing often uses chunking strategies to ensure long documents are broken into manageable and retrievable pieces. If the PDF is not present, then return the error. Query_embedding is used to convert the user query into embeddings.
best_score = -1
best_context = ""Initialise variables to track the best match.
for ref_text in reference_texts:
ref_embedding = model.encode(ref_text, convert_to_tensor=True)
similarity = torch.nn.functional.cosine_similarity(
question_embedding.unsqueeze(0), ref_embedding.unsqueeze(0)
).item()For each sentence from the PDF :
- Convert it into an embedding
- Compare it with the question using cosine similarity
- Higher similarity = better match
if similarity > best_score:
best_score = similarity
best_context = ref_textIf this sentence is the best match so far, update the best_score and best_context.
model_output = get_llm_response(best_context, question)
This line calls the LLM to get an answer. It sends the best context (the most relevant sentence from the PDF) and the question to the get_llm_response function, which returns the model's response based on that context.
Suggested Reads- Unlocking LLM Potential Through Function Calling
test_case = LLMTestCase(
input=question,
actual_output=model_output,
context=[best_context],
retrieval_context=[best_context]
)
Wrap the input question, response, and matched context into a test case object.
hallucination_metric.measure(test_case)
faithfulness_metric.measure(test_case)Run the evaluation to generate:
- Hallucination score (is anything made up?)
- Faithfulness score (does it follow the context?)
return (
question,
best_context,
model_output,
f"Hallucination Score: {hallucination_metric.score:.2f}\nReason: {hallucination_metric.reason}",
f"Faithfulness Score: {faithfulness_metric.score:.2f}\nReason: {faithfulness_metric.reason}"
)Send back everything:
- Original question
- Best-matched context
- Fake response
- Similarity score
- Hallucination & Faithfulness result
Walk away with actionable insights on AI adoption.
Limited seats available!
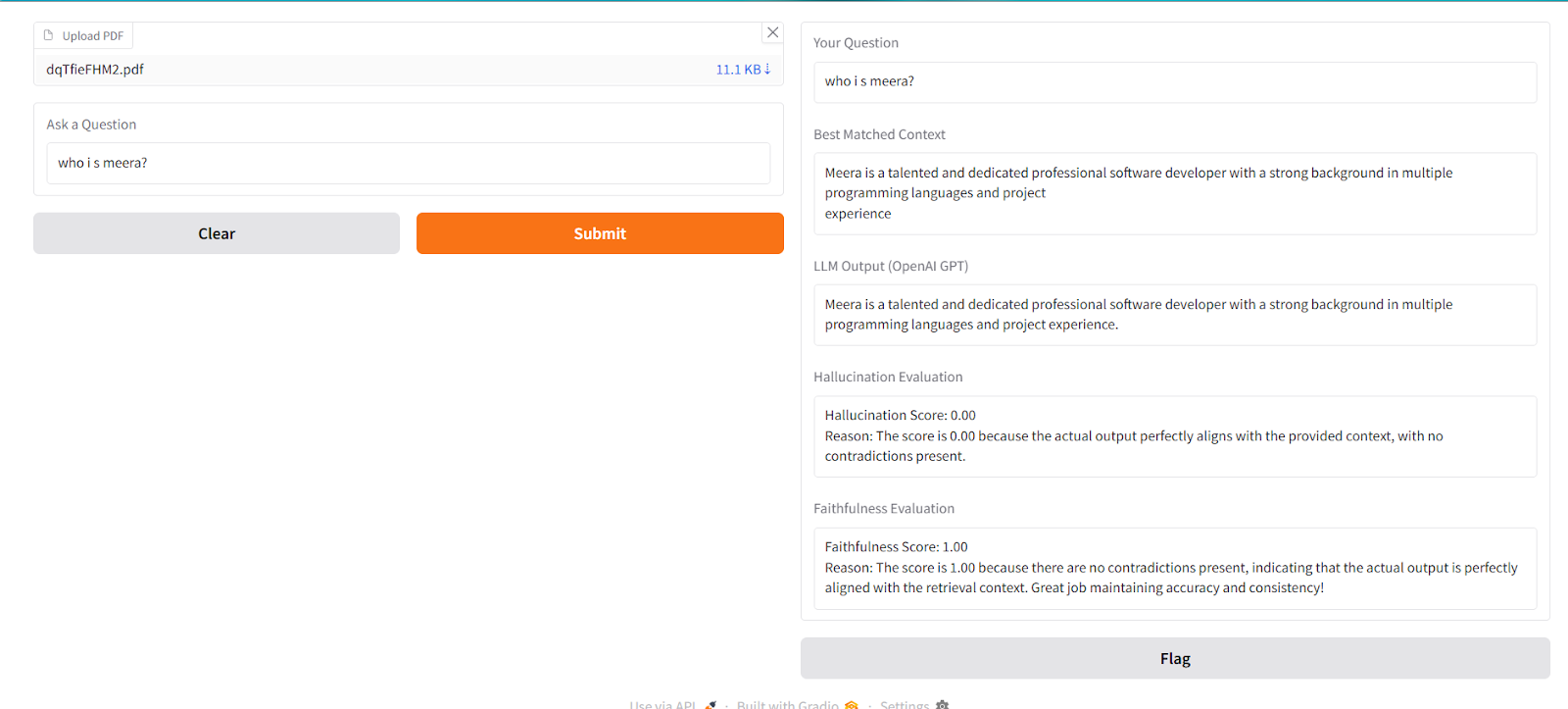
Step 7: Gradio Interface Setup
demo = gr.Interface(
fn=process_pdf_and_question,
inputs=[
gr.File(label="Upload PDF", file_types=[".pdf"]),
gr.Textbox(label="Ask a Question")
],
outputs=[
gr.Textbox(label="Your Question"),
gr.Textbox(label="Best Matched Context"),
gr.Textbox(label="LLM Output (OpenAI GPT)"),
gr.Textbox(label="Hallucination Evaluation"),
gr.Textbox(label="Faithfulness Evaluation")
],
title="PDF QA + Hallucination & Faithfulness Checker (OpenAI GPT)",
description="Upload a PDF and ask a question. The system finds the best context, gets a GPT answer, and evaluates hallucination & faithfulness using DeepEval."
)
demo.launch(share=True)
FAQ
What is the difference between hallucination and faithfulness in LLMs?
Hallucination refers to generating information that is factually incorrect or made up, while faithfulness measures whether the model stays aligned with the provided source without altering its meaning.
Why do LLMs hallucinate even when context is provided?
From my experience, hallucinations often happen due to token-level prediction, incomplete context retrieval, or weak alignment between the prompt and source. The model fills gaps with statistically likely text rather than verified facts.
How can hallucinations be detected automatically?
Hallucinations can be evaluated using techniques like Natural Language Inference (NLI), similarity checks, and specialized tools such as DeepEval that compare model outputs directly against the source context.
Is human evaluation still necessary?
Yes. Automated metrics are valuable, but I’ve found human review essential for catching subtle logical or contextual errors that automated systems may miss.
Conclusion
Detecting hallucinations and measuring faithfulness are essential steps in building reliable AI systems. Tools like DeepEval make it easier to identify when an LLM invents facts, drifts from source material, or produces ungrounded answers.
For teams using AI in document search, chatbots, automation, or customer workflows, this kind of evaluation improves trust, safety, and output quality. If you are planning production-grade AI systems, partnering with an experienced AI development company can help you build, test, and scale trustworthy solutions faster.

Varsha G
I'm an AI/ML Intern, passionate about building real-world applications using large language models, voice AI, and data privacy technologies.
Walk away with actionable insights on AI adoption.
Limited seats available!


