

As Large Language Models (LLMs) become core to chatbots, virtual assistants, and content generation, evaluation stops being optional. I’m writing this because many teams discover too late that a model can sound confident and still be wrong, inconsistent, or unsafe, especially when deployed across real users and edge cases.
This guide explains how to evaluate LLMs through a structured process using automated metrics and human judgment. It’s designed for developers, researchers, and AI builders who need to select, compare, tune, and monitor language models with measurable signals, not just impressions.
What is LLM Evaluation?
LLM evaluation is the process of measuring how well a language model performs against defined goals, such as correctness, relevance, reasoning quality, safety, and user experience. It checks not only whether answers are “right,” but whether they are clear, grounded, consistent with context, and appropriate for real-world use.
Why is LLM Evaluation important?
Without evaluation, a language model can sound confident while producing outputs that are false, misleading, biased, or unsafe. Fluency is not the same as reliability.
LLM evaluation helps teams detect failure modes early, compare models fairly, and validate improvements during fine-tuning or prompt changes. It ensures models are not only capable but also dependable, aligned to the use case, and safe to deploy.
What Are the Metrics of LLM Evaluation?
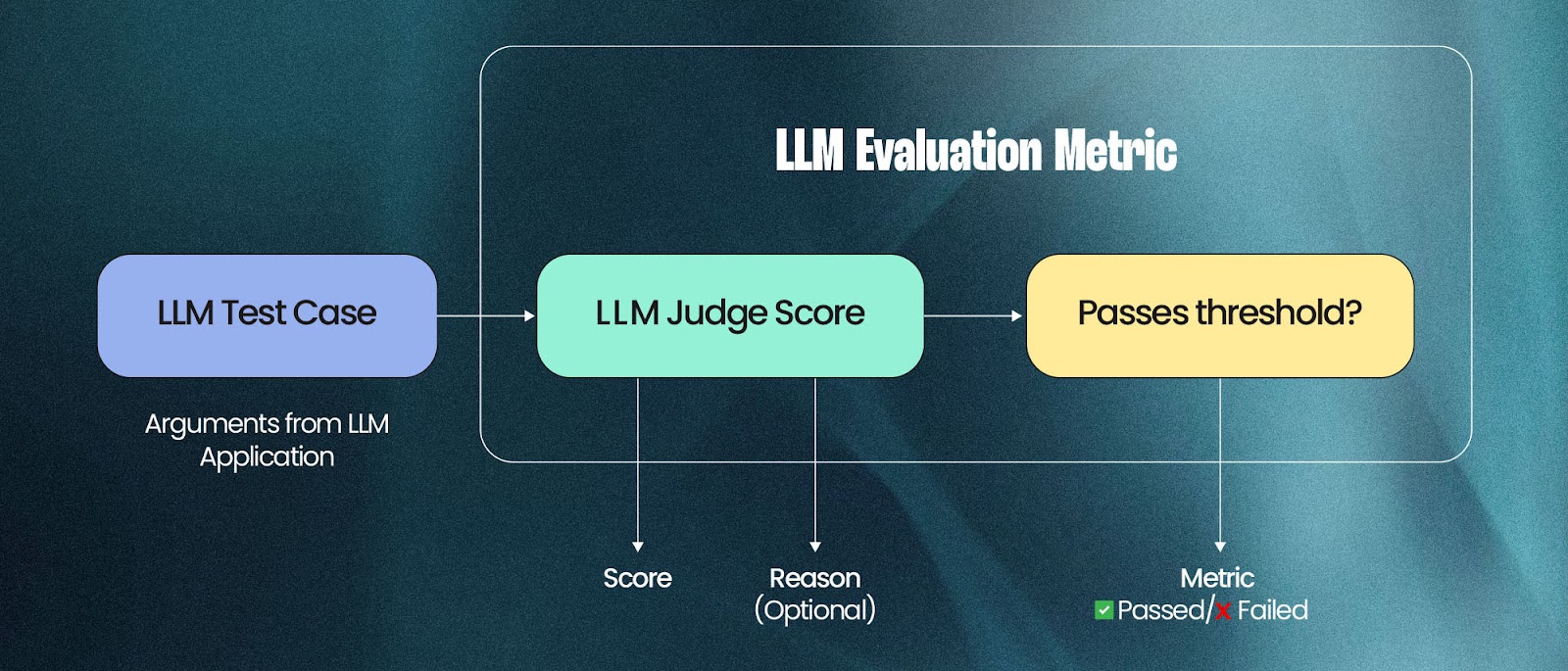
LLM evaluation metrics, such as answer correctness, semantic similarity, and hallucination focus on how well a language model is performing in terms of what actually matters.
These measures are useful because they allow you to translate the performance of your model into clear, measurable scores using standard LLM evaluation tools.
That way, we can compare LLMs to one another or track how one improves over time, whether we're evaluating the entire system or just the model itself.
Relevance Metrics
- These metrics estimate how close model output is to a reference or expected answer, most useful when a reliable ground truth exists.
- They are particularly useful in applications like summarization, translation, and question answering, where accuracy and proximity to the original meaning are paramount.
Accuracy and Performance Metrics Used to Evaluate LLMs

BLEU Score: Measures n-gram overlap between generated and reference text. Most useful for translation-like tasks, but can miss meaning when wording differs.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score: Measures the overlap of n-grams, words, or subsequences between a generated text and a reference text, and is commonly used in tasks such as summarization.
import os
from groq import Groq
from evaluate import load
from transformers import AutoTokenizer, AutoModelForCausalLM
# Initialize Groq client
client = Groq(api_key="api_key")
# Ask for user input
user_prompt = input("Enter your prompt for the LLM: ")
reference_text = input("Enter the reference (ideal) answer: ")
# Call Groq LLM
response = client.chat.completions.create(
model="llama3-70b-8192", # Choose a supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt}
],
temperature=0.7
)
# Extract the generated text
generated_text = response.choices[0].message.content
print("\nGenerated Response:\n", generated_text)
print("\nReference Text:\n", reference_text)
# --- BLEU SCORE CALCULATION ---
bleu = load("bleu")
bleu_result = bleu.compute(predictions=[generated_text], references=[reference_text])
print("\nBLEU Score:", bleu_result["bleu"])
# --- ROUGE SCORE CALCULATION ---
rouge = load("rouge")
rouge_result = rouge.compute(predictions=[generated_text], references=[reference_text])
print("\nROUGE Scores:")
for key, value in rouge_result.items():
print(f"{key}: {value:.4f}")F1 Score: Trade-off of precision and recall returning a single score to evaluate the classification performance using the overlapping tokens between the predicted answer and the real answer.
# --- F1 SCORE CALCULATION BASED ON TOKEN OVERLAP ---
def clean_and_tokenize(text):
# Convert to lowercase, remove punctuation, and split into tokens
text = text.lower()
text = re.sub(r'[^\w\s]', '', text)
return text.split()
# Tokenize both predicted and reference texts
pred_tokens = clean_and_tokenize(generated_text)
ref_tokens = clean_and_tokenize(reference_text)
# Create the combined token set
all_tokens = list(set(pred_tokens + ref_tokens))
# Build binary presence vectors
pred_vector = [1 if token in pred_tokens else 0 for token in all_tokens]
ref_vector = [1 if token in ref_tokens else 0 for token in all_tokens]
# Compute macro F1 score
f1 = f1_score(ref_vector, pred_vector, average='macro')
print("\nF1 Score (Token-Level, Macro):", round(f1, 4))METEOR Score: A key part of LLM evaluation methods, it combines precision, recall, synonym matching, stemming, and word order, providing a more flexible evaluation for machine translation.
import os
from groq import Groq
from nltk.translate.meteor_score import meteor_score
import nltk
# Download required NLTK resources
nltk.download('wordnet')
nltk.download('omw-1.4')
# Initialize Groq client with your API key
client = Groq(api_key="api_key")
# Ask user for input and reference text
user_prompt = input("Enter your prompt for the LLM: ")
reference_text = input("Enter the reference (ideal) answer: ")
# Call the Groq LLaMA3 model
response = client.chat.completions.create(
model="llama3-70b-8192",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt}
],
temperature=0.7
)
# Extract generated response
generated_text = response.choices[0].message.content
# Show outputs
print("\nGenerated Response:\n", generated_text)
print("\nReference Text:\n", reference_text)
# -------- METEOR Score Calculation --------
meteor = meteor_score([reference_text], generated_text)
print("\nMETEOR Score:", round(meteor, 4))BERTScore: Utilizes contextual embeddings from BERT (or similar models) to measure the semantic similarity of generated and reference texts using precision, recall, and F1 score.
# --- BERTScore CALCULATION ---
P, R, F1 = score([generated_text], [reference_text], lang='en')
print("\nBERTScore F1:", round(F1.mean().item(), 4))
print("\nBERTScore Precision:", round(P.mean().item(), 4))
print("\nBERTScore Recall:", round(R.mean().item(), 4))Perplexity: Measures how “surprised” a model is by a sequence (lower often indicates better next-token prediction). It does not directly measure factual accuracy or task success, so it’s best used alongside task metrics.
# --- PERPLEXITY CALCULATION ---
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Tokenize the input text
inputs = tokenizer(generated_text, return_tensors="pt")
# Compute the loss (negative log likelihood)
with torch.no_grad():
outputs = model(**inputs, labels=inputs['input_ids'])
loss = outputs.loss
# Perplexity is 2^loss
perplexity = torch.exp(loss).item()
print("\nPerplexity:", round(perplexity, 4))Human Evaluation Methods For LLMs
Many applications of Large Language Models (LLMs), such as open-ended Q&A, writing, coding, or conversational generation, often need human intuition and judgment to assess the quality of the produced content.

Walk away with actionable insights on AI adoption.
Limited seats available!
Automated metrics like BLEU, ROUGE, and token-level F1 are useful, but they often fail to capture qualities that matter in real usage, such as reasoning, instruction-following, tone, or safety. For open-ended tasks (Q&A, writing, coding, multi-turn chat), human evaluation is often required to judge whether output is actually usable.
Contextual Understanding: The model must leverage its output to respond to a given question or instruction, which may require complex reasoning or multi-turn dialog.
Creativity and Coherence: Humans are more favorable judges than machines when it comes to tasks such as content generation (e.g., story/essay composition), where one is judged based on the creativity, novelty and coherence.
Quality of Code: In tasks such as generating code, you need a person to judge how good the code is, whether or not it’s efficient, and whether or not it actually meets its functional purpose.
Ethics and Safety: Human beings can verify whether the response of the model is ethical, free from bias, and appropriate for many applications.
Pass@k Metric:
As part of modern LLM evaluation methods, the Pass@K metric measures whether the correct answer is present within the top k predictions generated by a model. Pass@k is commonly used for code generation evaluation. It measures whether at least one of the top-k generated solutions passes the correctness check (often unit tests). It works well when correctness can be validated automatically.
Code Below:
from groq import Groq
from sklearn.metrics import accuracy_score
# Initialize Groq client
client = Groq(api_key="api_key")
# Function to calculate Pass@K metric
def pass_at_k(predictions, ground_truth, k):
pass_count = 0
for pred, true in zip(predictions, ground_truth):
if any(true.lower() in p.lower() for p in pred[:k]):
pass_count += 1
return pass_count / len(predictions)
# Example queries and results
queries = ["What is the capital of France?", "Who won the 2020 Olympics?"]
ground_truth = ["Paris", "Japan"]
# Get predictions using Groq model
predictions = []
for query in queries:
# Modify the query to ask for a brief and precise answer
prompt = f"Please answer the following question precisely means give me one word: {query}"
# Send query to Groq for prediction using chat API
completion = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[{"role": "user", "content": prompt}],
temperature=0.3, # Lower temperature for more deterministic and concise answers
max_completion_tokens=1024,
top_p=1,
stream=False, # Set to False to get the full response
)
# Collect the predicted answers
predicted_answer = completion.choices[0].message.content
predictions.append([predicted_answer]) # Assuming single prediction per query
# Calculate Pass@5 (top 5 predictions)
k = 5
score = pass_at_k(predictions, ground_truth, k)
# Print results
print(f"Predictions: {predictions}")
print(f"Pass@{k}: {score}")Other Evaluations
Answer accuracy: Assessing whether the model returns the correct or most relevant answer (usually measured via direct comparison with a ground truth).
Fluency and Coherence: Whether the model provides fluent responses that are natural, grammatical, and coherent, i.e., as one would expect from a human in a conversation or text.
Relevance: measuring how well the model's response matches the context or task being discussed, taking care that the system response is on-topic with the user's needs or question.
Adequacy: determining if the model gives sufficient detail for a full answer (while not leaving out important stuff).
Helpfulness: Measuring how useful the model response is to the user for everyday use, for instance, such as assistants or customer service.
Engagement and Satisfaction: According to user interaction, assessing whether the model’s responses make the user engaged and satisfied with the interaction, which can be measured by user feedback or rating.
How LLM Evaluation Is Used in Real-World Applications
1. RAG Pipelines (Checking if Retrieved Content Improves the Model’s Answer)
One such attempt to enhance LLMs is through the use of Retrieval-Augmented Generation (RAG), which fuses external information retrieval and response generation in a model.
Walk away with actionable insights on AI adoption.
Limited seats available!
In this framework, when a query is asked, the matching documents (or relevant pieces of data) are retrieved, and the model reports an answer on the basis of both the query and retrieved contents.
Evaluation aims at deciding if returning content could enhance the quality of the retrieved response. If the model is able to successfully integrate up-to-date, accurate information, then we can see that it is capable of producing more precise and context-aware answers, and this is particularly the case for dynamic or fact-based tasks.
2. Educational AI Tools (Checking if Answers are Accurate and Understandable)
In educational AI systems, LLMs are assessed according to whether they can generate correct, easy-to-understand, and pedagogically effective responses, especially when paired with tools like text to speech to enhance accessibility and learning outcomes. The evaluation criteria make sure that the explanations produced by AI are not only factually correct but also tailored to the understanding of the audience.
This is especially important in areas such as math, science or language learning where clarity and ease of understanding can have a big effect on a student’s experience.
Such utilities evaluate if the AI support the learning process by generating educational and understandable content.
3. Task-Specific AI Agents (Validating Domain Performance in Tasks like Summarization or Factual QA)
Task-specific AI agents specialize in evaluating an LLM’s performance in specialized tasks, such as summarization or factual question answering.
In this approach, the performance of the model on domain-specific queries and the precision of the responses are evaluated. The aim is to verify whether the model is knowledgeable in such areas and that it can produce the right summaries or answers to factoid questions.
Such agents are challenged with complex, detailed questions in narrow domains (e.g., legal, medical or technical domains).
Best Practices for Evaluating LLM
- Define the Evaluation Objectives First: Clearly specify what you want to measure (e.g., accuracy, fluency, domain relevance) before even considering what measures to use. This makes sure the evaluation makes sense with the purposes of your model.
- Use Diverse Prompts and Scenarios: Evaluate by covering a variety of tasks and user intents to obtain realistic performance number and edge cases.
- Triangulate with Multiple Metrics: Avoid bearing eggs in one measurement basket. Combine machine metrics and human feedback for a more complete impression of model quality.
- Continuously Monitor and Re-evaluate: Your performance should be monitored and refined as models and data are updated. Continually re-evaluate to remain performance-oriented and relevant.
Conclusion
There is no single metric that can fully capture the quality of LLM outputs. Most automated metrics measure isolated aspects such as word overlap, precision, or probability, while often missing meaning, usefulness, and real-world applicability.
Effective LLM evaluation starts with clearly defined goals, followed by selecting metrics that align with those goals and complementing them with human judgment where automated tools fall short, particularly in areas like reasoning, tone, and ethical safety.
A strong evaluation strategy combines quantitative signals with qualitative review to ensure language models are not only powerful, but also reliable, context-aware, and safe for real-world deployment.

Dharshan
Passionate AI/ML Engineer with interest in OpenCV, MediaPipe, and LLMs. Exploring computer vision and NLP to build smart, interactive systems.
Walk away with actionable insights on AI adoption.
Limited seats available!


