

Tokenization is one of the most fundamental concepts in Natural Language Processing (NLP), yet it is often misunderstood until you start working directly with language models. When I first began building with NLP systems, I realized that tokenization silently controls cost, context limits, and model behavior more than most people expect.
In this article, I’ll break down what tokenization is, why it matters, and how it works using a clear, practical example.
What is Tokenization?
Tokenization is the process of splitting text into smaller units called tokens so machines can process language efficiently. These tokens may represent whole words, subwords, characters, or other linguistic units, depending on the tokenizer design.
The purpose of tokenization is not just to split text; it is to convert human language into structured components that can later be mapped into numerical representations for machine learning models.
In modern NLP systems, tokenization directly influences how a model interprets, stores, and processes input.
Why is Tokenization Important?
Machine learning models do not understand raw text. They operate entirely on numbers. Tokenization serves as the bridge between natural language and numerical computation.

It is the first operational step in converting text into embeddings or model inputs.
Tokenization impacts:
- Context window limits
- API cost (token-based pricing)
- Model performance on rare words
- Prompt efficiency
Without tokenization, text cannot be processed, embedded, or analyzed by NLP systems. It forms the structural foundation of every language model pipeline.
How Tokenization Works
Let’s walk through a practical example to understand how tokenization works in real systems. Consider the sentence:
"f22 Labs: A software studio based out of Chennai..."
Tokenization typically follows two structured steps.
Step 1: Splitting the Sentence into Tokens
The first step in tokenization is breaking the sentence into smaller units. Depending on the tokenizer used, these tokens can be:

Walk away with actionable insights on AI adoption.
Limited seats available!
Words: Breaks text into complete words and punctuation.
["f22", "Labs", ":", "A", "software", "studio", "based", "out", "of", "Chennai", ".", "We", "are", "the", "rocket", "fuel", "for", "other", "startups", "across", "the", "world", ",", "powering", "them", "with", "extremely", "high-quality", "software", ".", "We", "help", "entrepreneurs", "build", "their", "vision", "into", "beautiful", "software", "products", "."]
Subwords: Splits words into smaller meaningful units. This is common in modern LLMs (BPE, SentencePiece).
The tokens might be more granular. For example, ["f22", "Lab", "s", ":", "A", "software", "studio", "based", "out", "of", "Chennai", ".", "We", "are", "the", "rock", "et", "fuel", "for", "other", "start", "ups", "across", "the", "world", ",", "power", "ing", "them", "with", "extremely", "high", "-", "quality", "software", ".", "We", "help", "entrepreneur", "s", "build", "their", "vision", "into", "beautiful", "software", "products", "."]
Characters: Splits every character individually, including spaces and punctuation.
For character-level tokenization, the sentence would be split into individual characters: ["f", "2", "2", " ", "L", "a", "b", "s", ":", " ", "A", " ", "s", "o", "f", "t", "w", "a", "r", "e", " ", "s", "t", "u", "d", "i", "o", " ", "b", "a", "s", "e", "d", " ", "o", "u", "t", " ", "o", "f", " ", "C", "h", "e", "n", "n", "a", "i", ".", " ", "W", "e", " ", "a", "r", "e", " ", "t", "h", "e", " ", "r", "o", "c", "k", "e", "t", " ", "f", "u", "e", "l", " ", "f", "o", "r", " ", "o", "t", "h", "e", "r", " ", "s", "t", "a", "r", "t", "u", "p", "s", " ", "a", "c", "r", "o", "s", "s", " ", "t", "h", "e", " ", "w", "o", "r", "l", "d", ",", " ", "p", "o", "w", "e", "r", "i", "n", "g", " ", "t", "h", "e", "m", " ", "w", "i", "t", "h", " ", "e", "x", "t", "r", "e", "m", "e", "l", "y", " ", "h", "i", "g", "h", "-", "q", "u", "a", "l", "i", "t", "y", " ", "s", "o", "f", "t", "w", "a", "r", "e", ".", " ", "W", "e", " ", "h", "e", "l", "p", " ", "e", "n", "t", "r", "e", "p", "r", "e", "n", "e", "u", "r", "s", " ", "b", "u", "i", "l", "d", " ", "t", "h", "e", "i", "r", " ", "v", "i", "s", "i", "o", "n", " ", "i", "n", "t", "o", " ", "b", "e", "a", "u", "t", "i", "f", "u", "l", " ", "s", "o", "f", "t", "w", "a", "r", "e", " ", "p", "r", "o", "d", "u", "c", "t", "s", "."]
Most large language models rely on subword tokenization because it balances vocabulary efficiency and flexibility when handling rare or domain-specific terms.
Step 2: Mapping Tokens to Numerical IDs
After tokenization, each token is mapped to a unique numerical ID using a predefined vocabulary. This vocabulary assigns a fixed number to every known token. For example:
Vocabulary:
{"f22": 1501, "Labs": 1022, ":": 3, "A": 4, "software": 2301, "studio": 2302, "based": 2303, "out": 2304, "of": 2305, "Chennai": 2306, ".": 5, "We": 6, "are": 7, "the": 8, "rocket": 2307, "fuel": 2308, "for": 2309, "other": 2310, "startups": 2311, "across": 2312, "world": 2313, ",": 9, "powering": 2314, "them": 2315, "with": 2316, "extremely": 2317, "high-quality": 2318, "products": 2319, "entrepreneurs": 2320, "build": 2321, "their": 2322, "vision": 2323, "into": 2324, "beautiful": 2325}Token IDs:
[1501, 1022, 3, 4, 2301, 2302, 2303, 2304, 2305, 2306, 5, 6, 7, 8, 2307, 2308, 2309, 2310, 2311, 2312, 2313, 9, 2314, 2315, 2316, 2317, 2318, 2301, 5, 6, 2320, 2321, 2322, 2323, 2324, 2325]At this stage, the model no longer sees text. It processes a sequence of numerical identifiers that represent the structured form of the original sentence.
This numerical transformation enables neural networks to compute patterns, relationships, and meaning.
Real-World Tokenization
To analyze the tokens and token IDs for your example sentence using OpenAI's tokenizer, you can follow these steps:
1. Visit the Tokenizer Tool: Go to OpenAI's Tokenizer to access the tool.
2. Input Your Sentence: Enter your example sentence in the text box.
View Tokens and IDs: The tool will display the tokens and their corresponding token IDs. Each word or subword will be split into tokens as per the GPT tokenizer's rules, and you can see how the sentence breaks down.
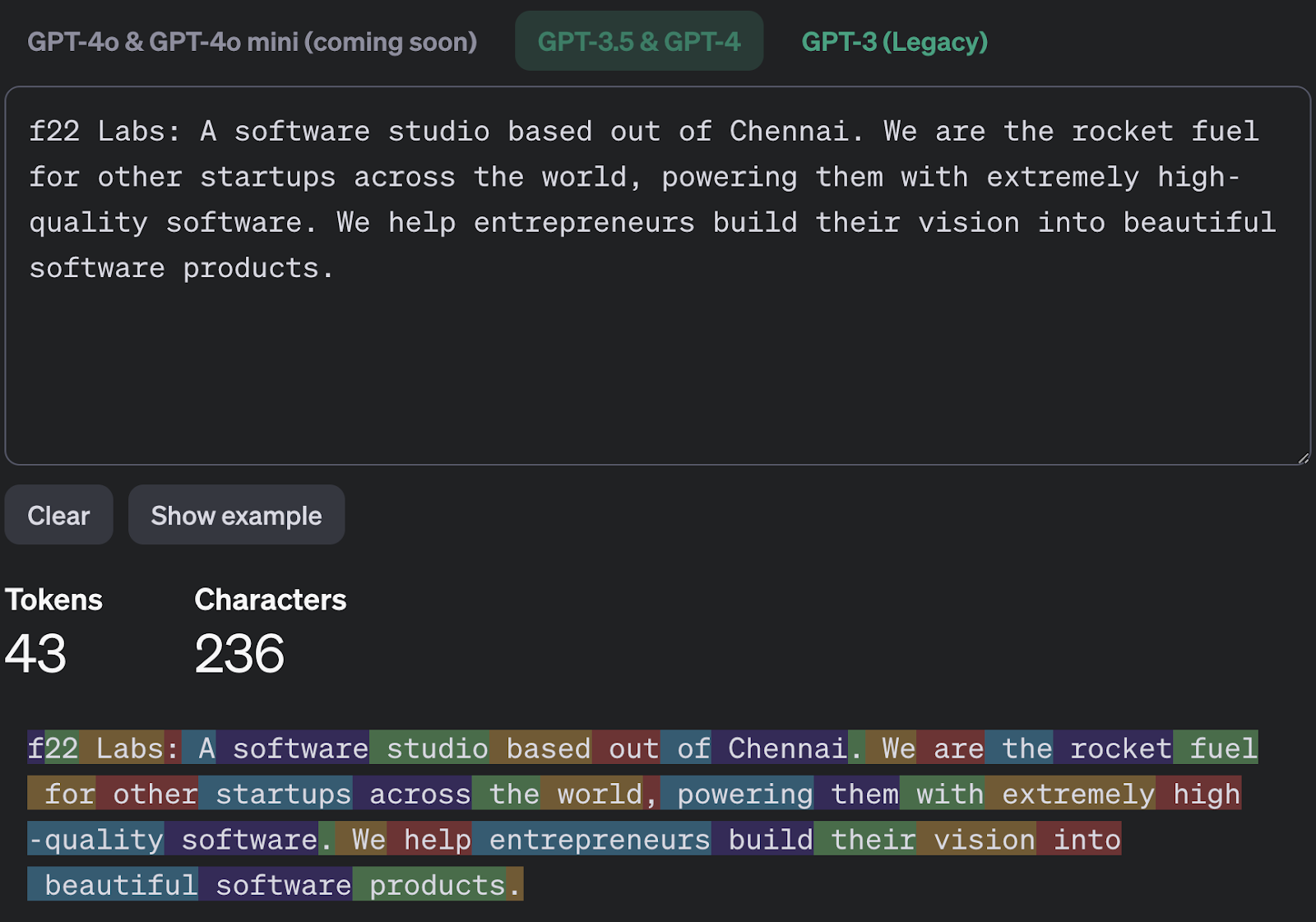
Token IDs

This exercise helps you understand:
- Why certain words split unexpectedly
- How token count affects cost
- How prompts approach context limits
Walk away with actionable insights on AI adoption.
Limited seats available!
For a broader understanding of how models use these tokens.
Suggested Reads- What is a Large Language Model (LLM)
FAQ
What is tokenization in NLP?
Tokenization is the process of splitting text into smaller units called tokens so that models can process language numerically.
Why does token count matter in LLMs?
Token count determines context length limits and directly impacts API cost and processing performance.
What type of tokenization do modern LLMs use?
Most modern LLMs use subword tokenization methods such as Byte Pair Encoding (BPE) or SentencePiece.
What is a token ID?
A token ID is the numerical representation assigned to a token within a model’s vocabulary.
Do different models use different tokenizers?
Yes. Each model may use a different tokenizer, which can result in different token splits and counts.
Conclusion
Tokenization is the foundational layer of Natural Language Processing. It transforms raw language into structured tokens and numerical IDs that machine learning models can process.
Whether you are building chat systems, working with embeddings, or optimizing prompts, understanding tokenization helps you control cost, context usage, and model efficiency.
It may appear to be a preprocessing step, but it influences nearly every downstream decision in modern AI systems.

Ajay Patel
Hi, I am an AI engineer with 3.5 years of experience passionate about building intelligent systems that solve real-world problems through cutting-edge technology and innovative solutions.
Walk away with actionable insights on AI adoption.
Limited seats available!


