How to Analyse Documents Using AWS Services

Imagine needing to extract structured data from thousands of documents every day, such as customer forms, invoices, medical records, or contracts. Manually processing this volume is inefficient, error-prone, and operationally unsustainable.
When writing this guide, I wanted to clarify how AWS document analysis services can transform document-heavy workflows into scalable, automated systems.
AWS provides powerful OCR capabilities through services like Amazon Textract, combined with advanced NLP services such as Amazon Comprehend and Amazon Comprehend Medical. Together, they enable structured extraction, contextual understanding, and actionable insights from unstructured documents.OCR technology enables the extraction of text from images, scanned documents, or PDF files. For a deeper look at how OCR works across different tools, you can check our detailed OCR models comparison guide.
AWS offers a range of NLP services such as Amazon Comprehend, Amazon Comprehend Medical, and Amazon Transcribe, which enable the analysis of text for insights, sentiment, entities, and more. NLP allows AWS to go beyond simple text extraction and understand the context, meaning, and relationships within the text.
By combining OCR and NLP, AWS can perform comprehensive document analysis. First, OCR extracts the text from documents, including scanned images or PDFs. Then, NLP processes the extracted text to understand its meaning, identify key entities or terms, and extract relevant information. This combined approach enables AWS to accurately interpret and extract information from various types of documents, ranging from simple forms to complex reports or contracts.
By automating the process of document analysis with AWS services, organizations can streamline their workflows, reduce manual effort, and increase efficiency.
Understanding AWS Document Analysis Services
Core AWS Services for Scalable Document Analysis
1. Amazon Textract:
Amazon Textract is a fully managed machine learning service designed to extract text, structured fields, tables, and signatures from scanned documents and PDFs with minimal configuration. It can also identify the structure of the document, such as forms and tables. Here are the key features of Amazon Textract:
- Raw Text: Extracts text in its unstructured format.
- Layout: Detects and identifies various sections of the document, such as headers, footers, paragraphs, figures, text headers, and more.
- Forms: Recognizes and identifies fields within forms, extracting key-value pairs.
- Tables: Identifies tables within a document and extracts the information contained within them.
- Queries: Retrieves information from the document based on specified keywords or questions.
- Signatures: Identifies and extracts signatures from documents.
2. Amazon Comprehend
Amazon Comprehend is an NLP service that analyses extracted text to identify entities, sentiment, key phrases, and relationships, enabling contextual interpretation beyond simple OCR. It can perform tasks like entity recognition, sentiment analysis, and topic modelling. Here are the key features of Amazon Comprehend:
- Key-phrase Extraction: It identifies and extracts key phrases from text. Key phrases represent the main topics or themes, helping to summarize and understand the core content.
- Sentiment Analysis: Analyzes text to determine the overall sentiment expressed. It classifies text as positive, negative, neutral, or mixed, providing insights into customer reviews, social media posts, and other text forms.
- Syntax Analysis: Analyzes the grammatical structure of text. It provides information about individual words, their parts of speech, and their relationships, useful for parsing sentences and understanding text dependencies.
- Entity Recognition: Identifies and extracts specific entities mentioned in the text. The entities include people, organizations, locations, dates, and other named entities.
- Language Detection: Identifies the language used in the text. Can detect multiple languages within a text, useful for multilingual datasets and diverse text sources.
- PII Identification: Detects and redacts personally identifiable information (PII) in text. It is useful for ensuring privacy in customer emails, support tickets, product reviews, social media, and more.
- Targeted Sentiment: Provides granular sentiment insights by identifying sentiment (positive, negative, neutral, or mixed) towards specific entities within text.
- Custom Classification: Allows users to create custom classification models tailored to their business needs. This enables training of models using custom data to classify text based on specific criteria.
3. Amazon Comprehend Medical
Amazon Comprehend Medical extends NLP capabilities into healthcare-specific analysis, extracting clinical entities, ICD-10 concepts, medications, and PHI from medical documents while maintaining HIPAA eligibility, such as doctors’ notes, patient records, and clinical trial reports. It is a HIPAA Eligible Service. Here are the key features of Amazon Comprehend Medical:
1. Entities: Inspect clinical text for various medical entities. This returns specific information about these entities, such as category, location, and confidence score.
2. ICD-10-CM concepts: Detects medical conditions listed in patient records. It links these conditions to normalized concept identifiers in the ICD-10-CM knowledge base.
3. RXNorm concepts: Identifies medications listed in patient records. It links medications to normalized concept identifiers in the RxNorm database from the National Library of Medicine.
4. SNOMED-CT concepts: Detects possible medical concepts as entities. It links these concepts to codes from the Systematized Nomenclature of Medicine, Clinical Terms (SNOMED-CT) ontology.
5. PHI: Detects Protected Health Information (PHI) in clinical text. It helps in identifying and managing sensitive health data to ensure privacy and compliance.
Key Features and Capabilities
- Scalability and Performance: These services are architected for automatic scaling, allowing document analysis pipelines to handle fluctuating workloads without manual infrastructure management, ensuring high performance even with large volumes of documents. This makes it suitable for businesses of all sizes, from startups to enterprises.
- Integration with AWS Ecosystem: These document analysis services seamlessly integrate with other AWS services, such as Amazon S3 for storage, AWS Lambda for serverless processing, and Amazon SageMaker for custom machine learning models. This integration simplifies the creation of comprehensive document-processing workflows.
- Customization and Flexibility: All the above AWS services gave extensive customization options, such as custom vocabularies in Amazon Transcribe and custom entity recognizes in Amazon Comprehend. This allows businesses to tailor the services to their specific needs and improve accuracy for specialized applications
- Security and Compliance: It provides strict restrictions and features such as encryption, access control, and compliance with regulations like HIPAA for healthcare data.
Use Cases For AWS Document Analysis Services
AWS document analysis services support automated extraction and processing across industries, including finance, healthcare, legal, and customer service, enabling structured data capture from invoices, applications, medical records, and contracts, medical records, prescriptions, legal documents and chat interactions to understand customer sentiment, identify common issues, and improve service quality.
This can automate and enhance their document processing workflows, leading to increased efficiency and accuracy. A few services that we can use are:
- Financial Services
- Healthcare
- Legal and Compliance
- Customer Service
Getting Started with AWS Document Analysis
Step 1: Create an AWS Account
Step 2: Set Up IAM Roles and Permissions
Step 3: Install and Configure AWS CLI
Uploading documents to AWS for analysis
1. Prepare Your Documents
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Ensure that your documents are in a supported format (e.g., PDF, JPEG, PNG). High-quality scans with clear text will yield better results
2. Upload to Amazon S3
Amazon Simple Storage Service (S3) is used to store documents. Create an S3 bucket and upload your documents.
3. Set Up S3 Bucket Permissions
Configure bucket policies to ensure that the necessary AWS services can access your documents. This might involve setting up bucket policies and access control lists (ACLs).
Document Analysis Workflow on AWS
A production-grade AWS document analysis workflow consists of structured stages designed for accuracy, reliability, and scalability. Each stage plays a crucial role in ensuring that documents are processed accurately and efficiently, providing valuable insights and data for your business.

1. Pre-processing
Pre-processing ensures document quality, format consistency, and structural organisation before extraction begins. This step is crucial for improving the accuracy of text extraction and ensuring consistency across different document types.
- Convert documents to a consistent format such as PDF or TIFF. This ensures uniformity and compatibility with text extraction tools.
- Adjust contrast and brightness levels and apply filters to improve the quality of scanned images. High-quality images lead to better OCR results.
- Categorize and label documents appropriately. For example, separate invoices from receipts and application forms. This organization helps in automating workflows and processing documents based on their type.
- Split multi-page documents if necessary and ensure each page is properly indexed and sequenced. This is particularly important for documents like contracts or reports.
2. Text extraction: Extracting relevant information from documents
Once documents are pre-processed, the next step is to extract text and data using Amazon Textract.
- Extracts all data from documents as text, forms, tables, etc., identifying key-value pairs and tabular data.
- Process multiple documents simultaneously to save time and increase throughput
- Implement mechanisms to detect and handle errors during text extraction, such as retrying failed extractions or flagging documents for manual review.
3. Data organisation and storage: Managing extracted data efficiently
After extracting text and data, it's important to organize and store it for easy access and analysis.
- Save extracted data in Amazon S3 for secure and scalable storage.
- Load structured data into databases like Amazon RDS or Amazon DynamoDB for efficient querying and analysis.
- Tag documents with metadata to improve searchability and categorization.
- Index the data for faster retrieval and to support complex queries.
Suggested Reads: Streaming Videos With AWS Elastic Transcoder
4. Insights: Text Analysis with Amazon Comprehend
After text extraction, Amazon Comprehend applies NLP to derive entities, sentiment, and contextual meaning from structured data outputs and a deeper understanding.
- Identify entities such as people, organizations, dates, and locations in the extracted text
- Determine the sentiment of the text (e.g., positive, negative, neutral). Helpful for understanding customer feedback or social media sentiment.
- Specialized service for extracting information from medical documents. Identifies entities such as medications, medical conditions, and treatments.
5. Post-processing: Refining extracted data for accuracy and usability
Post-processing involves refining extracted data to ensure accuracy and readiness for further use.
- Implement automated and manual correction procedures for common OCR errors.
- Filter out irrelevant data and sort the remaining data into meaningful categories.
- Save refined data back into the database or storage system for further processing.
- Create dashboards and reports to share insights with stakeholders.
Let’s visualize how the workflow of Document analysis using AWS services will work from the below image.
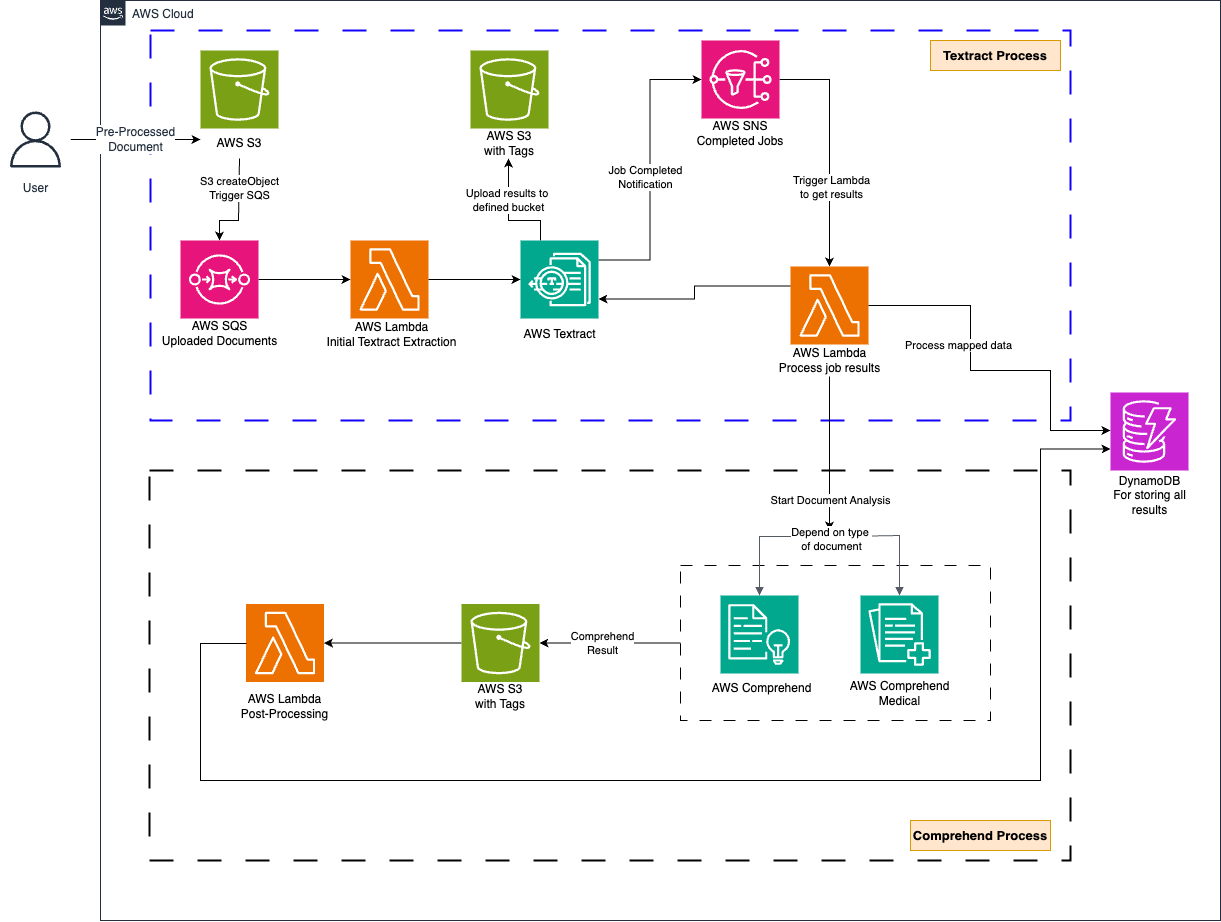
The diagram illustrates a serverless architecture for document processing using AWS services. This involves the use of both Amazon Textract and Comprehend. Here's a step-by-step breakdown of the process:
Textract Process
- The User uploads a document to an S3 bucket (let's call it `S3 Input Bucket`).
- The S3 bucket sends an event to an SQS queue upon the document upload.
- The SQS queue triggers a Lambda function named start-textract-extraction.
- This Lambda function initiates an Amazon Textract job to extract text from the document.
- Once the Textract extraction is completed, the results are uploaded to a specified S3 bucket with a given prefix, and an SNS topic is notified.
- The SNS topic triggers another Lambda function named process-textract-result with the S3 key of the Textract result.
- This Lambda function processes the Textract result and saves the processed data to a database.
Comprehend Process
- Based on the type of document, the Lambda function triggers AWS Comprehend for general text analysis or AWS Comprehend Medical for medical documents
- AWS Comprehend performs Natural Language Processing (NLP) to understand the content, while AWS Comprehend Medical is used for extracting medical information from the document.
- The results from Comprehend are stored in an S3 bucket.
- The creation of the Comprehend result object in the S3 bucket triggers another Lambda function named process-comprehend-result.
- This Lambda function processes the comprehended result based on the confidence score
- Finally, all processed and filtered results are stored in an Amazon DocumentDB for querying and further analysis.
Summary
- The architecture integrates S3 for storage, SQS and SNS for event-driven messaging, Lambda for serverless orchestration, Textract for extraction, Comprehend for NLP analysis, and DocumentDB or DynamoDB for structured storage.
- SQS and SNS are used for messaging and notifications.
- AWS Lambda functions are used extensively for processing at various stages.
- Amazon Textract is used for extracting text and data from documents.
- AWS Comprehend and AWS Comprehend Medical is used for NLP and medical text processing.
- Amazon DocumentDB is used for storing the final results.
Estimated Cost
AWS document analysis services operate on usage-based pricing, allowing cost optimization based on volume, region, and processing configuration, so you only pay for what you use. Charges are also based on the region. Here’s the estimated cost for processing and analyzing 1,000 documents using the services depicted in the workflow.
- Amazon S3
- Storage:
- Assume 1,000 documents of 1 MB each.
- Storage required: 1,000 MB (1 GB).
- Data Transfer:
- Data transfer between AWS services in the same region is free.
- Minimal cost for data retrieval from S3.
- Storage:
- Amazon SQS
- Request Pricing:
- Assume 1,000 documents per month.
- Standard Queue: $0.40 per million requests.
- Approximate cost: (1,000 * 2) / 1,000,000 * $0.40 = $0.0008
- Request Pricing:
- AWS Lambda
- Invocation Cost:
- Assume each Lambda function is invoked 1,000 times per month.
- Each invocation duration is 1 second with 512 MB memory.
- Free Tier: 1 million requests and 400,000 GB-seconds compute time.
- If usage exceeds Free Tier, the cost is calculated based on $0.20 per 1 million requests and $0.0000166667 per GB-second.
- For simplicity, assuming within Free Tier.
- Invocation Cost:
- Amazon Textract
- Text Extraction:
- Assume 1,000 pages per month.
- Text extraction cost: $1.50 per 1,000 pages.
- Forms and tables cost: $50 per 1,000 pages.
- Total cost: $1.50 + $50 = $51.50
- Text Extraction:
- Amazon SNS
- Notification Cost:
- Assume 1,000 notifications per month.
- Cost: $0.50 per million publish requests.
- Approximate cost: 1,000 / 1,000,000 * $0.50 = $0.0005
- Notification Cost:
- Amazon DynamoDB
- Storage and Write/Read Capacity:
- Assume storage requirement is minimal (1 GB).
- Write requests: 1,000 items.
- Read requests: 1,000 items.
- Using On-Demand mode: $1.25 per WCU and $0.25 per RCU per million requests.
- Approximate cost: (1,000 / 1,000,000 * $1.25) + (1,000 / 1,000,000 * $0.25) = $0.0015
- Storage and Write/Read Capacity:
- Amazon Comprehend
- Text Analysis:
- Assume 1,000,000 characters (10,000 units).
- Cost: $0.0001 per unit.
- Approximate cost: 10,000 * $0.0001 = $1.00
- Text Analysis:
- Amazon Comprehend Medical
- Medical Text Analysis:
- Assume 1,000,000 characters (10,000 units).
- Cost: $0.00125 per unit.
- Approximate cost: 10,000 * $0.00125 = $12.50
- Medical Text Analysis:
So, the cost as per service will be
- Amazon S3: Minimal (within Free Tier)
- Amazon SQS: $0.0008
- AWS Lambda: Minimal (within Free Tier)
- Amazon Textract Pricing: $51.50
- Amazon SNS: $0.0005
- Amazon DynamoDB: $0.0015
- Amazon Comprehend: $1.00
- Amazon Comprehend Medical: $12.50
Total Cost: $51.50 + $0.0008 + $0.0005 + $0.0015 + $1.00 + $12.50 = $65.00/Month
Note: Keep in mind that actual costs may vary based on specific usage patterns and any additional AWS services that might be used in your setup.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Advanced Techniques and Best Practices
Advanced optimisation techniques improve accuracy, throughput, compliance alignment, and cost efficiency in large-scale document analysis environments, ensuring you achieve high performance, accuracy, security, and scalability
1. Optimizing performance and accuracy through customization
- Configure Textract to focus on specific document types (e.g., forms, tables) for more accurate text extraction.
- Process documents in batches to optimize resource usage and reduce processing time.
- Use parallel processing where possible to speed up large-scale document analysis.
- Postprocess extracted data to correct common OCR errors and normalize results.
2. Handling complex document formats and structures
- For Structured Documents: Use Textract’s table and form recognition capabilities to accurately extract data from structured documents like invoices, purchase orders, and tax forms
- For Unstructured Documents: Leverage Comprehend’s NLP features to extract meaning from unstructured text, identifying key phrases, entities, sentiment, and more
- For Other languages (Multilingual): We can utilize Comprehend’s language detection and translation features to handle documents in multiple languages.
- For Complex layout: With unique layouts, consider using Amazon Textract’s AnalyzeDocument API with specialized configurations to handle custom fields and annotations.
3. Ensuring data security and compliance
- Use AWS Key Management Service (KMS) to encrypt documents at rest and in transit.
- Ensure that the extracted data is also encrypted and securely stored.
- Implement fine-grained access controls using AWS Identity and Access Management (IAM) to restrict access to sensitive data.
- Use IAM roles to ensure that only authorized services and users can access the data.
- Utilize AWS’s compliance programs and resources to help meet regulatory requirements.
4. Handling Large-Scale Document Analysis Efficiently
- Use AWS Lambda and Step Functions to build scalable, serverless workflows that can handle varying workloads.
- Leverage S3 event notifications to trigger processing workflows automatically.
- Use Amazon CloudWatch to monitor the performance of your document analysis workflows and set up alerts for any issues.
- Implement comprehensive logging with AWS CloudTrail to track access and changes to your document processing environment.
- Use AWS Cost Explorer and AWS Budgets to monitor and manage expenses.
FAQ
1. What AWS services are used for document analysis?
Amazon Textract for OCR, Amazon Comprehend for NLP, and Amazon Comprehend Medical for healthcare-specific text analysis.
2. How does AWS Textract differ from traditional OCR?
Textract extracts structured data such as forms and tables, not just raw text, making it more suitable for business workflows.
3. Can AWS document analysis scale to thousands of documents daily?
Yes. AWS services are designed to scale automatically using serverless components like Lambda, S3, and SQS.
4. Is AWS document analysis HIPAA compliant?
Amazon Comprehend Medical and related services are HIPAA eligible when configured correctly.
5. What is the estimated cost of AWS document analysis?
Costs vary by usage but can start around $65 per month for processing 1,000 documents based on Textract and Comprehend pricing.
6. How do I improve accuracy in AWS document analysis?
Improve document quality, use structured preprocessing, apply custom entity recognition, and implement post-processing validation.
Conclusion
Modern organisations require scalable, accurate document analysis to remain competitive. Manual processing introduces bottlenecks and inconsistency, while AWS services such as Textract and Comprehend enable automated, AI-driven extraction and contextual analysis.
By designing a structured workflow using AWS’s serverless architecture, organisations can reduce operational costs, improve data accuracy, and gain actionable insights from previously unstructured documents.
Strategic implementation, starting small and scaling progressively, ensures measurable efficiency gains without unnecessary infrastructure complexity. Manual methods are time-consuming and prone to errors, making it difficult to manage and extract valuable information consistently. Thankfully, AWS services like Amazon Textract and Amazon Comprehend provide powerful solutions to these challenges with advanced AI and machine learning.
Using AWS's document analysis services offers significant benefits, such as increased efficiency and scalability, high accuracy, cost-effectiveness, and deeper insights from your data. Automating the extraction and analysis of information from documents allows you to focus on more important tasks and make better decisions.
Now is the perfect time to start using AWS document analysis services to transform your business processes. Begin by exploring the AWS documentation and tutorials for Amazon Textract and Amazon Comprehend. Start with a small project to get comfortable with the capabilities and then gradually scale up. Don’t be afraid to experiment with different configurations and integrations to find the best solutions for your specific needs.
The potential savings in time and resources, combined with enhanced insights from automated document analysis, make AWS services a valuable asset for any modern business. Take the Leap today and revolutionize your document analysis processes with AWS.
By following these steps, you can keep your business ahead of the competition and maximize the value of your data. Embrace the future of document analysis with AWS and unlock new opportunities for growth and efficiency.

Shubham Ambastha
I'm a Senior Software Developer with 4.5+ years of experience in building optimized, cost-effective web applications. Passionate about coding and innovation, I create impactful tech solutions.


