

Which vector database should you choose for your AI-powered application: Qdrant or Milvus?
As the need for high-dimensional data storage grows in AI use cases like semantic search, recommendation systems, and Retrieval-Augmented Generation (RAG), vector databases have become essential. I’ve seen teams get stuck here because both tools look “right” on paper, but behave differently once you care about latency, throughput, and operational complexity.
In this article, I compare Qdrant vs Milvus based on architecture, performance, and ideal use cases. You’ll get a practical breakdown of insertion speed, query latency, indexing, and throughput, backed by benchmark tests using the SQuAD dataset.
Whether you’re building lightweight prototypes or enterprise-scale systems, this guide is meant to reduce guesswork and help you choose the tool that fits your workload, tech stack, and scalability goals.
What is a Vector Database?
Vector databases are designed to store, index, and query high-dimensional vector embeddings. Unlike traditional databases built around structured rows and columns, vector databases are designed to handle unstructured data (like text, images, and audio) through their numerical embeddings.
The core problem they solve is similarity search. Given a query vector, the goal is to retrieve the most similar vectors in the dataset. In practice, this is handled using approximate nearest neighbor (ANN) algorithms that trade perfect accuracy for speed and scalability.
Vector DB use case:
RAG systems: storing document embeddings for context retrieval with LLMs. Effective chunking strategies in Rag are often applied here to break large documents into manageable pieces, improving retrieval accuracy.
- Semantic search: identifying content that is conceptually similar within text corpus
- Recommendation systems: matching users preferences and items via embeddings
- Image/video search: matching visual similarity within multimedia systems
- Anomaly detection: identifying outliers in high-dimensional feature spaces
Now we are going to look at the top vector databases that power modern AI applications, including traditional solutions like Qdrant and Milvus, as well as newer offerings like Amazon S3 Vectors. We'll compare their key features, performance, and ideal use cases. This comparison will help you choose the most suitable vector DB for your specific project requirements.
What is Qdrant?
Qdrant is a vector similarity search engine. It offers a service that is production ready, with an easy-to-use API that allows you to store, search, and manage points (i.e., vectors), It is optimized for high-performance similarity search, so it is mostly used for AI/ML purposes like semantic search, recommendation systems, and Retrieval-Augumented Generation (RAG).
Qdrant Architecture Overview:
The diagram below represents a high-level overview of the main components of Qdrant that are important to understand before evaluating its performance and filtering capabilities. Here are the terminologies you should get familiar with.
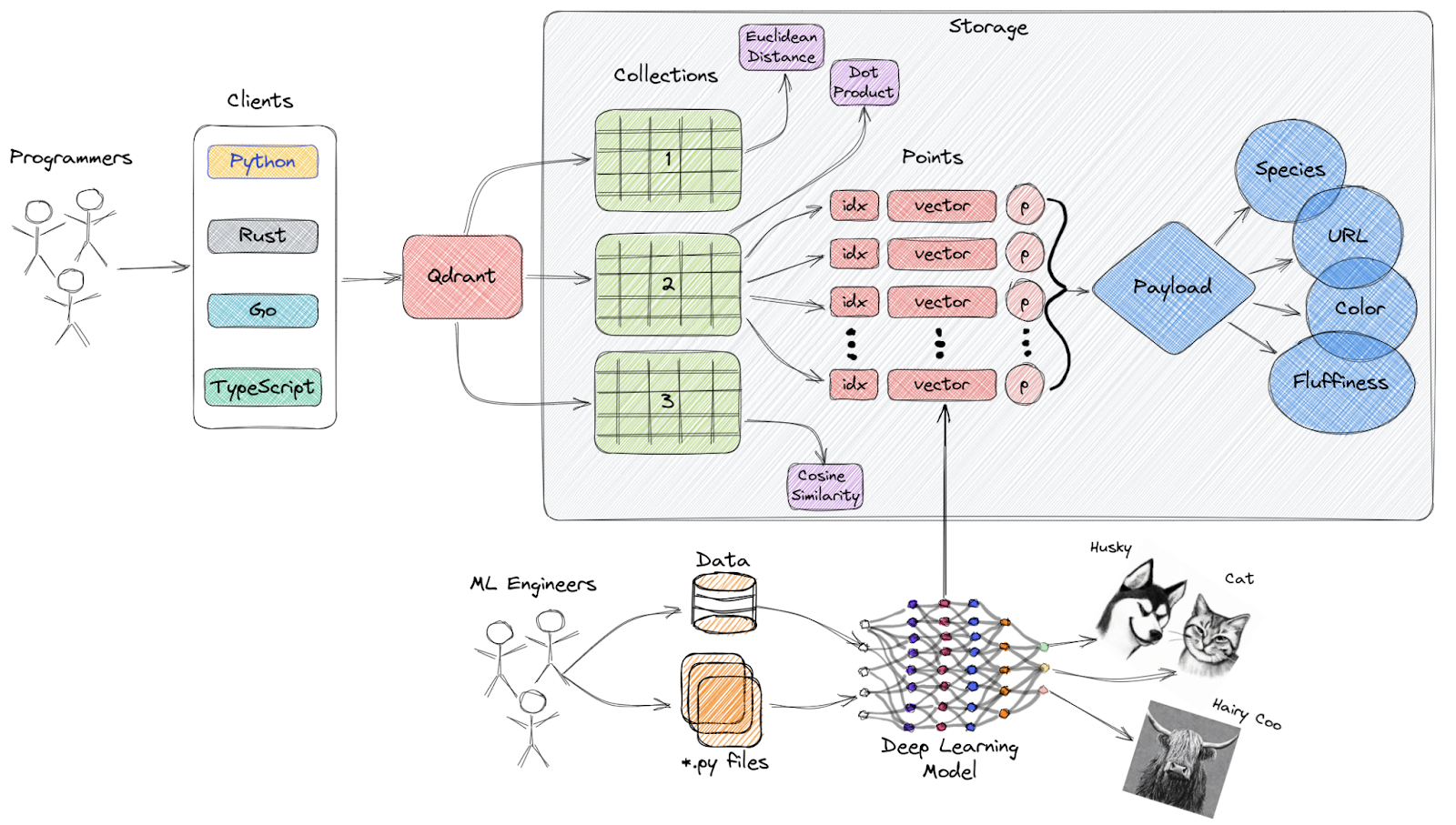
Collections: A collection is a named set of points which all consist of a vector and optional metadata (payload). All vectors in a collection have the same dimensionality and a same distance metric is used for comparisons. Qdrant also allows you to use named vectors, which each point may store multiple vectors that may all have different dimensions and metrics while using the same ID.
Distance Metrics: These define how vector similarity is measured on a collection. The metric(s) has to be determined when the collection is created. The choice is made based on how the vector was generated. It will be usually determined by the embedding model or neural network used.
Points: Points are the core data structure inside Qdrant. Each point consists of:
→ ID: A unique identifier for the point.
→ Vector: A high-dimensional representation of the data (e.g., text, image,audio).
→ Payload: An optional JSON object that stores additional metadata, useful for filtering and enriching search results.
Storage Options:
→ In-memory storage: Keeps vectors in RAM for faster access; disk is only used for persistence.
→ Memmap storage: It will create a virtual address space that is connected with the file on disk.
Clients: Qdrant provides client libraries in several programming languages so developers can easily integrate vector search into their webpages, applications, etc.
What is Milvus?
Milvus, originally developed by Zilliz and now part of the LF AI & Data Foundation, takes a cloud-native approach that prioritizes scalability and high-throughput workloads. From the ground up, Milvus was designed for the specific purpose of maximizing large-scale implementations, which means it is focused on scalability, performance, and enterprise-grade tools for management.
Milvus Architecture Overview
Milvus’s cloud-native and highly decoupled system architecture ensures that the system can continuously expand as data grows:
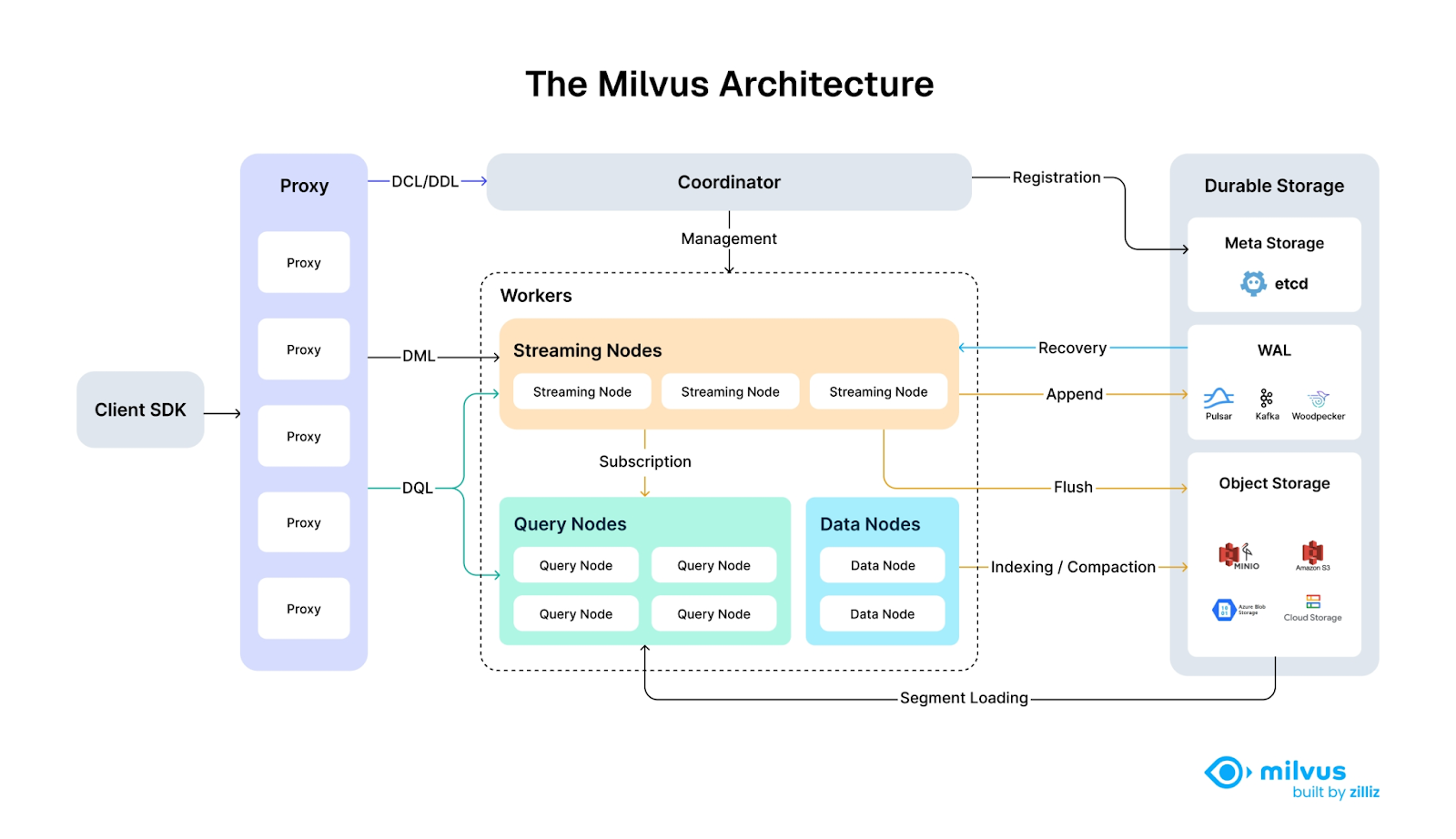
Milvus employs a disaggregated architecture where compute, storage, and metadata are decoupled and can be scaled independently. This design is powerful for large-scale systems, but it also introduces more operational complexity compared to simpler deployments. It is implemented as a microservices architecture with separate components for coordination, data nodes, query nodes and index nodes.

Walk away with actionable insights on AI adoption.
Limited seats available!
The architecture allows for both standalone deployments and distributed deployments. In distributed mode, Milvus employs cloud-native technologies, like Kubernetes, for orchestration and employs message queues for reliable messaging between components.
Milvus takes a "cloud-native" approach, built entirely with distributed and massively scalable computing in mind. It can operate in two modes:
- Standalone Mode: Single instance for development and small deployments
- Cluster Mode: Distributed architecture for production workloads
Core Components of Milvus
Milvus uses microservices across many components:
→ Coordinator Services: Manage metadata and coordinate operations
→ Worker Nodes: Handle data processing and queries
→ Storage: Separate compute from storage for better scalability
→ Message Queue: Ensure reliable data processing
Comparison Between Qdrant and Milvus
| Feature | Qdrant | Milvus |
License | Apache 2.0 | Open Source (LF AI & Data Foundation) |
Written In | Rust | C++ & Go |
Vector Index Support | HNSW (Hierarchical Navigable Small World) | IVF, HNSW, Flat, ANNOY, DiskANN (via FAISS) |
Storage Backend | RocksDB | MinIO, local, etc. |
Payload Filtering | Rich (metadata filtering supported) | Yes (but limited compared to Qdrant) |
Distance Metrics | Cosine, Euclidean, Dot Product | Euclidean, Inner Product, Cosine, Hamming |
gRPC/REST API Support | REST, gRPC, WebSocket | gRPC primarily |
Docker Support | Yes | Yes |
Cloud Hosting | Qdrant Cloud (official) | Zilliz Cloud (official) |
Deployment | Simple (single binary) | Complex (K8s native) |
Community & Docs | Growing, developer-friendly | Very mature, widely adopted |
Best For | Lightweight, metadata-rich use cases | Large-scale high-performance applications |
The architectural differences between these two databases are significant and directly affect how they behave under real workloads. Qdrant is built in Rust, which gives it both memory-safety and speed. Its concern with developer experience opens the door for teams of all sizes. Qdrant's rich filtering on payload makes it extremely strong as a search engine for applications that need to search based on complex metadata.
Milvus has chosen a different direction with implemented language, and many indexing types. The many index types available on Milvus create greater flexibility for developers to optimize for specific use cases, and the mature ecosystem on Milvus has many available tools and integrations.
Benchmark Setup: How Qdrant and Milvus Were Tested
To make this comparison practical, I ran benchmark tests using realistic data and query patterns that reflect common semantic search and RAG workloads.
The test datasets used here are SQuAD (Stanford Question Answering Dataset), which comprises over 1,00,000 question-answer pairs derived from Wikipedia articles. For that dataset, the embeddings were generated using sentence-transformers with 384-dimensional vectors. This is a common scenario for many semantic search and RAG applications using contemporary embedding models.
For search evaluation, we executed Top-3 nearest neighbour queries, as this is the common pattern for recommendation systems and semantic search applications.
The benchmarks tested the four most important metrics in production:
- Insertion Time for inserting bulk data
- Indexing Time for making the data searchable
- Query Latency for a great user experience
- Throughput for concurrent requests
Benchmarking Qdrant and Milvus: Insertion, Latency & QPS
Qdrant Performance
In my benchmark tests, Qdrant showed the following performance characteristics.
- Insertion Time: 41.27 seconds for the entire dataset
- Query Latency: 94.52 ms average response time
- Throughput (QPS): 4.70 queries per second
Qdrant showed consistent performance with predictable resource usage patterns. The insertion process showed little variation with virtually no spikes in memory or CPU usage, making it a viable option for environments with limited resources.
Milvus Performance
In my benchmark tests, Milvus showed performance characteristics that align with its focus on bulk ingestion and high concurrency. While Milvus showed excellent performance, it was predominantly optimized for a different set of use cases:
- Insertion Time: 12.02 seconds for data ingestion
- Indexing Time: 0.60 seconds for indexing
- Query Latency: 40.00 ms ms average response
- Throughput (QPS): 46.33 queries per second
Milvus appears to have superior performance for bulk operation and concurrent query handling. Milvus is also able to separate the indexing step from the initial data loading, and so search performance can be optimized after the data has been ingested.
Performance Analysis of Milvus and Qdrant
Insertion Performance
Milvus unquestionably leads in the insertion space, with data ingestion in 12.02 seconds compared to Qdrant's 41.27 seconds. There's a 3.4x performance advantage, which is very important for use cases that constantly update data or as part of a real-time ingestion pipeline.
This performance difference results from Milvus's optimized bulk-insertion methods, of which both Qdrant and Milvus use, and Milvus's distributed architecture, which parallelizes data processing across nodes.
If applications need to continuously update their vector databases due to new content, the performance led by Milvus equates to better user experiences and lower operational costs.
Indexing Time
Milvus provides a number of primary custom indexing strategies that can affect query performance quite a bit. The 0.60-second indexing time in the test shows just how fast the system can re-optimize the data for search operations. The separation of insertion with indexing could also allow for different designs of data pipelines.
Qdrant integrates indexing into the insertion process, which simplifies operations but may impact insertion speed. Conversely, Qdrant ensures that data is available for search operations without indexes needing to run on a secondary logic.
Walk away with actionable insights on AI adoption.
Limited seats available!
Query Latency:
Qdrant achieves a much better performance for individual query latency with response times at 94.52ms, compared to Milvus at 250.01ms. This difference of almost 2.6x resulting response time provides much better systems for real-time applications, where customers are accustomed to interacting with the system in less than a second.
This reduced latency is a consequence of the optimized query processing pipeline, and the more efficient memory consumption in comparison to Milvus. In instances of interactive interfaces, such as chatbots, recommendation systems, or search ever-changing search interfaces, the latency is directly related to end-user experience.
Throughput (QPS)
Milvus wins in throughput scenarios with 46.33 queries per second performance compared to Qdrant's performance of 4.70 QPS. This gives Milvus almost a 10x advantage and makes Milvus a far better candidate for environments with high concurrency in which many users are concurrently querying the system.
The high throughput of Milvus is attributed to its optimized ANN (i.e., Approximate Nearest Neighbor) engine and its batched search capabilities. Both are utilized which allows Milvus to serve many queries in a single batch smartly and tolerates traffic spikes with minimal performance degradation.
Choosing Between Qdrant and Milvus
| Use Case | Best Choice |
Real-time search with rich filtering | Qdrant |
High-throughput vector search | Milvus |
Simpler setup and deployment | Qdrant |
Complex indexing and vector types | Milvus |
Lightweight semantic search services | Qdrant |
Large-scale production workloads | Milvus |
Choosing between Qdrant and Milvus depends on your use case, infrastructure, and operational comfort. When I evaluate this decision, I focus on whether low latency or high throughput is the primary requirement.
Qdrant is ideal for low-latency applications that require rich metadata filtering. Its lightweight, developer-friendly setup makes it a great choice for teams looking to get started quickly without the complexity of managing distributed systems.
Milvus, on the other hand, excels in high-throughput environments with demanding indexing needs. Its ability to handle 10x more queries per second makes it a solid option for large-scale, production-grade systems.
Evaluate your operational capabilities and long-term goals. If simplicity and speed-to-deploy matter most, go with Qdrant. If performance and scalability are your priorities, Milvus is the better fit.
Conclusion
Both Qdrant and Milvus are strong vector databases, but they are built for different priorities. I put this comparison together to make those trade-offs clearer without relying only on feature lists.
Qdrant fits best when low latency, rich metadata filtering, and simpler deployment matter most. Milvus is a better choice for high-throughput systems where bulk ingestion and large-scale concurrency are the main concerns.
The right choice depends on your workload, infrastructure, and how you expect the system to scale over time. Once those constraints are clear, the decision between Qdrant and Milvus becomes much easier.
Frequently Asked Questions
1. What are the key differences between Qdrant and Milvus?
Qdrant is optimized for low-latency search and rich metadata filtering, making it ideal for real-time, interactive applications. Milvus, in contrast, offers higher throughput and supports more indexing options, which are better suited for large-scale deployments with heavy concurrency and bulk data ingestion.
2. Which vector database is better for Retrieval-Augmented Generation (RAG) applications?
Qdrant is often preferred for RAG due to its fast query latency and advanced metadata filtering, which helps refine context retrieval more accurately. However, Milvus can also work well if your application needs to handle a very large volume of queries concurrently.
3. Can I use Qdrant or Milvus for semantic search on text data?
Yes, both Qdrant and Milvus support semantic search. Qdrant is especially effective for lightweight semantic search systems where metadata filtering and low-latency queries are important. Milvus offers more indexing flexibility and is better for large-scale implementations.
4. How does the performance of Qdrant and Milvus compare in benchmarks? In benchmark tests using the SQuAD dataset:
- Milvus showed better insertion speed and higher throughput (46.33 QPS).
- Qdrant had lower query latency (94.52 ms), making it ideal for responsive search tasks. Milvus is better for handling bulk operations, while Qdrant is optimized for real-time querying.
5. Is Qdrant or Milvus better for beginners starting with vector databases?
Qdrant is generally better suited for beginners due to its simple setup, lightweight architecture, and developer-friendly APIs. It can be deployed with a single binary and supports easy integration through REST and gRPC. Milvus, while powerful and scalable, has a more complex, microservices-based architecture that's better suited for experienced teams working on large-scale projects.

Shankari R
AI/ML Intern passionate about building intelligent systems using LLMs, NLP, and data-driven solutions. Skilled in Python and ML frameworks, with hands-on experience in Generative AI, vector databases, and model fine-tuning.
Walk away with actionable insights on AI adoption.
Limited seats available!


