

Data augmentation is a powerful technique in machine learning that involves creating modified versions of existing data to expand training datasets. It's a method to augment data without altering its core meaning or label, helping models learn more robust features and improve generalization.
This technique is widely used in image, text, and audio processing to enhance model performance, combat overfitting, and address data scarcity issues in AI and deep learning applications.
Do you know? - The concept of data augmentation was first popularized in the landmark 2012 paper "ImageNet Classification with Deep Convolutional Neural Networks" by Krizhevsky et al., which significantly improved image classification accuracy.
Why is Data Augmentation Important?
Data augmentation plays a crucial role in machine learning for several reasons:
1. Addresses Limited Data: It artificially expands datasets, reducing the need for expensive and time-consuming data collection.
2. Enhances Generalization: Exposing models to diverse variations of input data, it helps AI systems perform better on unseen data.
3. Mitigates Overfitting: Augmentation prevents models from memorizing training data, promoting learning of general patterns.
4. Balances Datasets: Helps in cases of uneven class distribution in classification problems.
5. Improves Data Privacy: Creates synthetic samples that retain statistical properties without exposing sensitive information.
Data augmentation is particularly valuable in domains where large, diverse datasets are challenging to obtain, making it a cost-effective method to boost model performance.
How Does Data Augmentation Work?
Data augmentation is a process that involves applying various transformations to existing data samples. The goal is to create new, diverse examples that can help machine learning models generalize better. Let's dive deeper into each type of augmentation and the overall process.
1. Image Augmentation
Image augmentation is perhaps the most widely used form of data augmentation, especially in computer vision tasks. Here's a more detailed breakdown of the techniques:
Geometric Changes
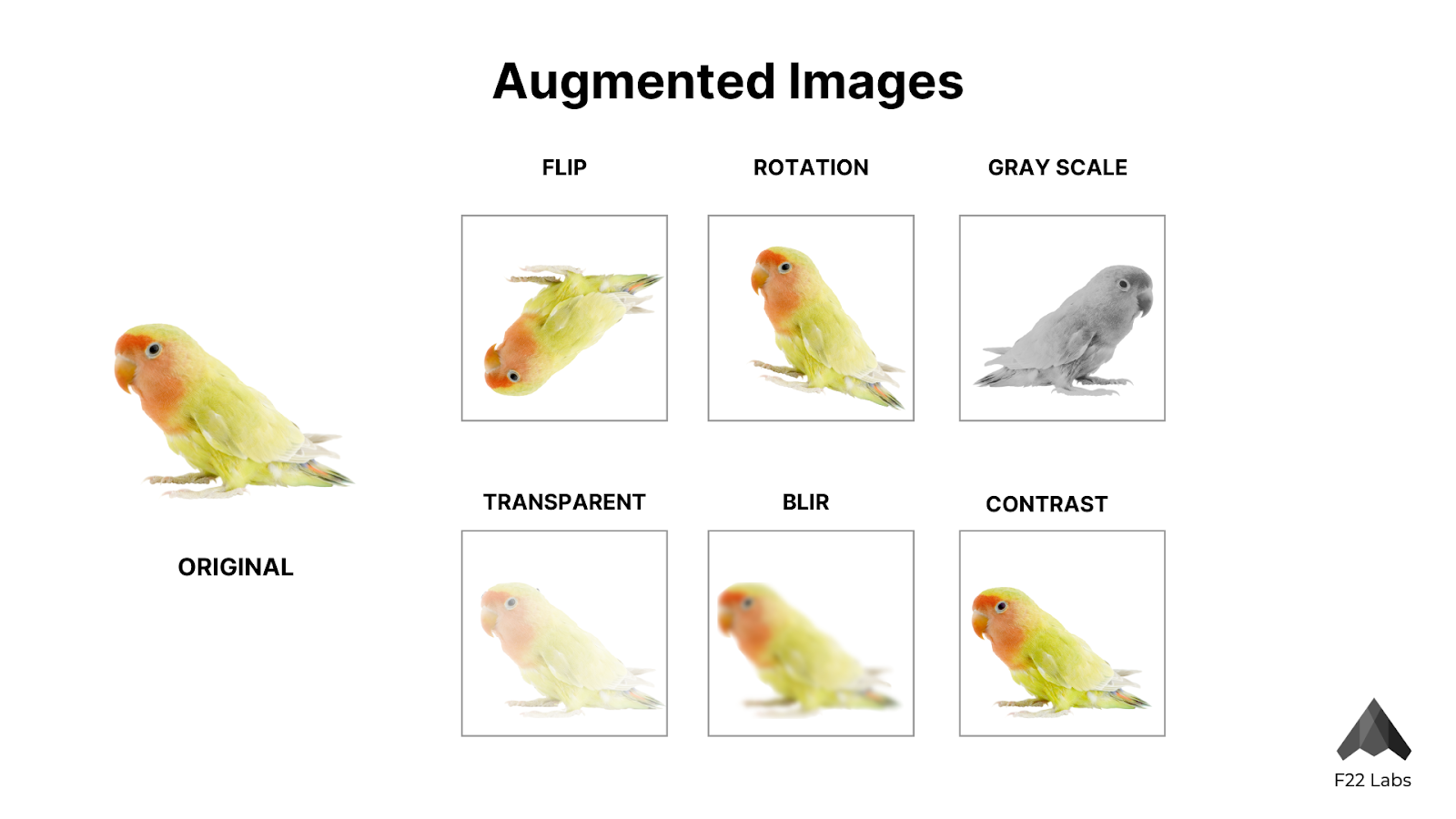
- Flipping: Horizontal or vertical mirroring of the image. This is particularly useful for objects that can appear in different orientations.
- Rotating: Turning the image by a certain angle. This can range from slight rotations (e.g., 5-15 degrees) to more dramatic ones (e.g., 90 or 180 degrees).
- Scaling: Resizing the image, either making it larger or smaller. This helps models become invariant to object size.
- Cropping: Selecting a portion of the image. This can help focus on specific features and simulate partial object views.
- Shearing: Slanting the image along an axis, which can help with perspective invariance.
Color Adjustments
- Brightness: Increasing or decreasing the overall lightness of the image.
- Contrast: Enhancing or reducing the difference between light and dark areas.
- Saturation: Adjusting the intensity of colors in the image.
- Hue: Shifting the color spectrum of the image.
- Color Jittering: Randomly changing multiple color properties simultaneously.
Noise and Filtering
- Gaussian Noise: Adding random noise following a Gaussian distribution.
- Salt and Pepper Noise: Randomly setting pixels to black or white.
- Blur: Applying Gaussian blur or other blurring techniques to simulate focus issues.
2. Text Data Augmentation
Text data augmentation is crucial for Natural Language Processing (NLP) tasks. Here's an expanded look at the techniques:
Lexical Level Changes
- Synonym Replacement: Substituting words with their synonyms. For example, "The cat is on the mat" could become "The feline is on the rug."
- Random Word Insertion: Adding new words to the text. For instance, "I love pizza" might become "I really love hot pizza."
- Random Word Deletion: Removing words randomly. "The quick brown fox" could become "The brown fox."
- Spelling Errors: Introducing common misspellings to make models more robust to real-world text.
Sentence Level Modifications
- Back-translation: Translating text to another language and then back to the original. This can introduce natural paraphrasing.
- Sentence Shuffling: Changing the order of sentences in a paragraph.
- Paraphrasing: Rewriting sentences to convey the same meaning in different words.
Advanced NLP Techniques
- Contextual Augmentation: Using language models to replace words based on context.
- Text Generation: Employing models like GPT to generate additional, contextually relevant text.
3. Audio Data Augmentation
Audio data augmentation is essential for speech recognition and sound classification tasks. Here's a more detailed look:
Time Domain Transformations
- Time Stretching: Changing the duration of the audio without affecting pitch.
- Time Shifting: Moving the audio clip forward or backward in time.
- Speed Perturbation: Altering the playback speed, which affects both time and pitch.
Frequency Domain Modifications
- Pitch Shifting: Changing the pitch without altering the tempo.
- Frequency Masking: Masking certain frequency bands to simulate occlusions.
Noise and Environmental Effects
- Background Noise Addition: Mixing in ambient sounds like cafe noise, street sounds, etc.
- Room Simulation: Applying reverb and echo to simulate different acoustic environments.
- Audio Mixing: Overlaying multiple audio samples.
The Data Augmentation Process
The process of implementing data augmentation is a crucial step in enhancing machine learning models. Let's dive deeper into each stage:
1. Analyze the Original Dataset
This initial step is foundational to the entire augmentation process. It involves:
- Data Profiling: Examine the statistical properties of your dataset. This includes understanding the distribution of features, identifying outliers, and recognizing patterns.
- Quality Assessment: Evaluate the quality of your data. Look for missing values, inconsistencies, or potential biases.
- Domain-Specific Analysis: Consider the unique characteristics of your data domain. For example, in medical imaging, you might need to preserve certain diagnostic features.
- Limitations Identification: Recognize where your dataset might be lacking. Are certain classes underrepresented? Are there scenarios your data doesn't cover?
Example: In a facial recognition dataset, you might notice a lack of images with varied lighting conditions or facial orientations.

2. Determine Suitable Augmentation Techniques
Choosing the right augmentation techniques is critical. This step involves:
- Relevance Assessment: Ensure the augmentation techniques align with real-world variations your model might encounter.
- Label Preservation: Select methods that don't alter the fundamental meaning or label of the data.
- Task-Specific Considerations: Tailor your choices to your specific machine learning task. Classification tasks might benefit from different augmentations compared to object detection tasks.
- Balancing Act: Decide on the degree of augmentation. Too little might not provide sufficient variety, while too much could introduce noise.
Example: For a bird species classification task, you might choose techniques like slight rotations, color jittering, and random cropping, but avoid extreme transformations that could make species identification impossible.
3. Apply Transformations
This is where the actual augmentation happens. Key considerations include:
- Implementation Strategy: Decide between on-the-fly augmentation during training or pre-computing augmented data.
- Randomization: Implement a system for randomly applying transformations. This could involve setting probability thresholds for each augmentation type.
- Chaining Transformations: Consider applying multiple augmentations sequentially. For instance, an image might be rotated, then have its brightness adjusted.
- Parameter Tuning: Carefully set the parameters for each augmentation. The degree of rotation, the intensity of color changes, etc., should be thoughtfully considered.
Example: In a text classification task, you might randomly apply synonym replacement to 20% of words, followed by random insertion of relevant words in 10% of sentences.
4. Create New, Synthetic Data Points
This step focuses on generating the augmented data:
- Volume Consideration: Decide how many augmented samples to create. This often depends on your original dataset size and the complexity of your model.
- Quality Control: Implement checks to ensure the augmented data remains valid and meaningful.
- Diversity Assurance: Aim for a wide range of variations to expose your model to diverse scenarios.
- Metadata Management: Keep track of which samples are augmented and how. This can be useful for later analysis.
Example: For an audio dataset of bird calls, you might generate five variations of each original recording, applying combinations of time stretching, pitch shifting, and background noise addition.
5. Combine Augmented Data with the Original Dataset
The final step involves integrating the new data:
- Balancing Strategy: Decide on the ratio of original to augmented data. Some approaches maintain a 1:1 ratio, while others might use more augmented data.
- Shuffling: Ensure the augmented data is well-mixed with the original data to prevent the model from learning artificial patterns.
- Validation Split Consideration: Be mindful of how you split your data for validation. Ensure augmented versions of validation data don't leak into the training set.
- Iterative Refinement: Consider this a dynamic process. You might need to adjust your augmentation strategy based on model performance.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
Example: In a medical imaging project, you might combine your original 10,000 X-ray images with 30,000 augmented versions, ensuring a good mix of original and synthetic data across all classes.
Do you know? - Google's AutoAugment, introduced in 2018, uses reinforcement learning to automatically find the best augmentation policies for a given dataset.
When Should You Use Data Augmentation?
Consider using data augmentation in the following scenarios:
1. Small Datasets: To artificially increase training data size
2. Expensive Data Collection: In domains like medical imaging or specialized industrial applications
3. Imbalanced Datasets: To generate additional samples for underrepresented classes
4. Overfitting Issues: To introduce variability and help models generalize better
5. Robustness Requirements: When models need to handle various input conditions (e.g., different lighting in computer vision tasks)
Always validate that augmentation improves your model's performance on test data, as inappropriate augmentation can sometimes introduce bias or noise.
Limitations of Data Augmentation
While powerful, data augmentation has several limitations:
1. Requires Domain Expertise: Choosing appropriate methods that preserve data's semantic meaning
2. Limited Novelty: May not create truly novel information, as it's based on existing data
3. Computational Cost: Some techniques can be resource-intensive for large datasets
4. Risk of Over-augmentation: Excessive transformations can lead to unrealistic data samples
5. Uneven Effectiveness: May not be equally beneficial across all data types or problem domains
Careful consideration and testing are necessary to ensure augmentation benefits model performance without introducing unwanted artifacts or biases.
Use Cases of Data Augmentation
Data augmentation has become a crucial technique across various machine learning domains, significantly improving model performance and generalization. Let's dive deeper into each use case:
1. Computer Vision
Computer vision is one of the primary fields benefiting from data augmentation. Here's how it's applied:
Image Classification
- Augmentation Techniques: Rotation, flipping, color jittering, random cropping
- Example: In plant disease detection, augmenting leaf images with various orientations and lighting conditions helps models recognize diseases more accurately in real-world scenarios.
- Impact: Studies have shown that proper augmentation can improve classification accuracy by 5-10% on benchmark datasets.
Object Detection
- Augmentation Techniques: Random scaling, translation, Mosaic augmentation (combining multiple images)
- Example: For autonomous drone navigation, augmenting training images with various object scales and positions improves detection of obstacles in diverse environments.
- Impact: Data augmentation has been crucial in improving the mean Average Precision (mAP) of object detection models, with some studies reporting up to 15% improvement.
Facial Recognition
- Augmentation Techniques: Slight rotations, brightness adjustments, partial occlusions
- Example: Augmenting face images with different expressions, lighting conditions, and partial coverings (like masks) enhances model robustness for real-world applications.
- Impact: Augmentation has been shown to reduce false positive rates in facial recognition systems by up to 25% in challenging conditions.
2. Natural Language Processing (NLP)
NLP tasks greatly benefit from data augmentation, especially in low-resource scenarios:
Text Classification
- Augmentation Techniques: Synonym replacement, random insertion/deletion, back-translation
- Example: In email spam detection, augmenting spam examples with synonym replacements helps models catch more sophisticated phishing attempts.
- Impact: Text augmentation can lead to a 3-7% increase in classification accuracy, particularly for minority classes.
Sentiment Analysis
- Augmentation Techniques: Word swapping, sentence restructuring, contextual augmentation using language models
- Example: Augmenting customer reviews with paraphrases helps sentiment analysis models understand diverse expressions of opinions.
- Impact: Proper augmentation can improve sentiment classification F1 scores by 2-5%, especially for nuanced sentiments.
Machine Translation
- Augmentation Techniques: Back-translation, syntax-based augmentation, paraphrasing
- Example: Augmenting parallel corpora with back-translated sentences improves translation quality for low-resource language pairs.
- Impact: Studies have shown BLEU score improvements of up to 2 points for low-resource languages using augmentation techniques.
3. Healthcare
Data augmentation is particularly valuable in healthcare due to limited and sensitive data:
Medical Imaging for Rare Conditions
- Augmentation Techniques: Rotation, scaling, elastic deformations, synthetic image generation using GANs
- Example: In rare cancer detection from MRI scans, augmenting the limited dataset helps models learn more robust features for accurate diagnosis.
- Impact: Augmentation has been shown to improve rare disease detection accuracy by up to 15% in some studies.
Disease Diagnosis
- Augmentation Techniques: Noise injection, simulated artifact addition, style transfer between different imaging modalities
- Example: Augmenting X-ray images with simulated lung nodules helps train more sensitive pneumonia detection models.
- Impact: Some studies report up to 10% improvement in diagnostic accuracy for certain conditions when using augmented training data.
4. Speech Recognition
Speech recognition models benefit greatly from augmentation to handle diverse acoustic conditions:
- Augmentation Techniques: Speed perturbation, pitch shifting, adding background noise, room impulse response simulation
- Example: Augmenting clean speech data with various background noises (cafe, street, etc.) improves model performance in real-world environments.
- Impact: Word Error Rate (WER) reductions of 5-15% have been reported in noisy conditions when using augmented training data.
5. Autonomous Vehicles
Data augmentation is crucial for training robust perception systems in autonomous vehicles:
- Augmentation Techniques: Weather simulation (rain, snow, fog), time-of-day changes, occlusion simulation
- Example: Augmenting clear-weather driving scenes with simulated adverse weather conditions improves object detection in challenging environments.
- Impact: Studies have shown up to 20% improvement in object detection accuracy in adverse weather conditions when training with augmented data.
Do you know? In 2019, researchers used data augmentation to improve the accuracy of skin cancer detection from dermatoscopic images, achieving performance comparable to expert dermatologists.
Augmented Data vs. Synthetic Data
While related, augmented data and synthetic data have distinct characteristics:
| Aspect | Augmented Data | Synthetic Data |
Source | Modified from real data | Generated from scratch |
Purpose | Expand existing datasets | Create entirely new datasets |
Realism | Generally more realistic | Can vary in realism |
Diversity | Limited by original data | Potentially more diverse |
Use Cases | Improving model generalization | Simulating rare scenarios, privacy preservation |
Both techniques have their place in AI development, often complementing each other in data-driven applications.
Data Augmentation Techniques for Text
Text data augmentation is crucial for improving the performance and robustness of Natural Language Processing (NLP) models. Let's dive deeper into each technique:
1. Lexical Level Augmentation
These techniques focus on word-level modifications:
Synonym Replacement
- Process: Replace words with their synonyms while maintaining the sentence's meaning.
- Example: Original: "The cat is sitting on the mat." Augmented: "The feline is resting on the rug."
- Impact: This can increase vocabulary diversity in the dataset, helping models learn broader word associations.
- Consideration: Use context-aware synonym replacement to maintain sentence coherence.
Random Word Insertion
- Process: Insert new words randomly into the sentence.
- Example: Original: "I love to read books." Augmented: "I really love to read interesting books often."
- Impact: Helps models learn to understand sentences with varied word counts and structures.
- Consideration: Ensure inserted words are contextually appropriate to avoid nonsensical sentences.
Random Word Deletion
- Process: Randomly remove words from the sentence.
- Example: Original: "The quick brown fox jumps over the lazy dog." Augmented: "Quick fox jumps over lazy dog."
- Impact: Improves model robustness to missing or implied information.
- Consideration: Maintain a balance to ensure the sentence retains its core meaning.
Spelling Errors Simulation
- Process: Introduce common misspellings or typos.
- Example: Original: "This is an excellent product." Augmented: "This is an excelent prodcut."
- Impact: Helps models handle real-world text with common errors.
- Consideration: Use a dictionary of common misspellings rather than random character changes.
2. Sentence Level Augmentation
These techniques modify entire sentences:
Back-translation
- Process: Translate the text to another language and then back to the original language.
- Example: Original (English): "The weather is nice today." Translated to French: "Le temps est beau aujourd'hui." Back to English: "The weather is beautiful today."
- Impact: Introduces natural paraphrases and alternative expressions.
- Consideration: Choose intermediate languages carefully to maintain semantic similarity.
Paraphrasing
- Process: Rewrite the sentence to convey the same meaning using different words.
- Example: Original: "She completed the task quickly." Augmented: "The assignment was finished by her in no time."
- Impact: Exposes models to diverse ways of expressing the same concept.
- Consideration: Ensure paraphrases maintain the original sentiment and key information.
Sentence Shuffling
- Process: Change the order of sentences in a paragraph or document.
- Example: Original: "John went to the store. He bought milk. Then he returned home." Augmented: "He bought milk. John went to the store. Then he returned home."
- Impact: Helps models learn to understand context beyond immediate sentence boundaries.
- Consideration: Be cautious with texts where sentence order is crucial for meaning.
3. Document Level Augmentation
These techniques operate on entire documents:
Topic-guided Text Generation
- Process: Generate new text passages based on the topic of the original document.
- Example: Original: A short article about climate change. Augmented: Additional paragraphs discussing related environmental issues.
- Impact: Expands the dataset with thematically related content.
- Consideration: Ensure generated content aligns well with the original document's focus.
Document Summarization and Expansion
- Process: Create summaries or expand documents with additional details.
- Example: Original: A detailed product review. Augmented: A concise summary of the review, or an expanded version with more pros and cons.
- Impact: Helps models learn to handle varying levels of detail and abstraction.
- Consideration: Maintain the core message and sentiment in summaries or expansions.
Partner with Us for Success
Experience seamless collaboration and exceptional results.
4. Advanced Techniques
These methods leverage more sophisticated NLP models:
Contextual Augmentation Using Language Models
- Process: Use pre-trained language models to suggest context-appropriate word replacements.
- Example: Original: "The bank is by the river." Augmented: "The shore is by the stream."
- Impact: Generates more natural and context-aware augmentations.
- Consideration: Ensure the language model is appropriate for your domain.
Data Augmentation Using GPT or BERT Models
- Process: Leverage large language models to generate entirely new text or fill in masked portions of existing text.
- Example: Original: "Customer service was [MASK]." Augmented: "Customer service was excellent." or "Customer service was disappointing."
- Impact: Can generate diverse, high-quality augmentations that maintain style and context.
- Consideration: Be mindful of potential biases in the pre-trained models.
These methods help NLP models understand semantic variations and improve performance in tasks like sentiment analysis, text classification, and machine translation. They're particularly useful when dealing with limited textual data or imbalanced datasets in specific domains.
Audio Data Augmentation Techniques
Audio data augmentation is crucial for improving the robustness and performance of speech recognition systems and sound classification models. Let's dive deeper into each technique:
1. Time Domain Techniques
These techniques manipulate the temporal aspects of the audio signal:
Time Stretching
- Process: Alter the duration of the audio without changing its pitch.
- Example: A 5-second audio clip of "Hello" is stretched to 6 seconds without changing the voice pitch.
- Impact: Helps models handle variations in speaking rates and improves robustness to tempo changes.
- Implementation: Often uses phase vocoder algorithms or resampling techniques.
- Consideration: Extreme stretching can introduce artifacts, so typically limited to ±20% of original duration.
Time Shifting
- Process: Move the audio clip forward or backward in time, often with wrapping.
- Example: Shift a bird call recording 0.5 seconds earlier, wrapping the end to the beginning.
- Impact: Teaches models to recognize sounds regardless of their exact timing in the audio clip.
- Implementation: Simple circular shift of the audio samples.
- Consideration: Useful for tasks where the timing of the sound within the clip isn't critical.
Speed Perturbation
- Process: Change the playback speed, affecting both duration and pitch.
- Example: Speed up a speech recording by 10%, making it shorter and slightly higher-pitched.
- Impact: Simulates variations in speaking speed and pitch, improving model generalization.
- Implementation: Often done by resampling the audio signal.
- Consideration: Commonly used factors are 0.9, 1.0, and 1.1, effectively tripling the dataset.
2. Frequency Domain Techniques
These techniques manipulate the frequency characteristics of the audio:
Pitch Shifting
- Process: Alter the pitch of the audio without changing its tempo.
- Example: Shift a male voice slightly higher to sound more feminine, or vice versa.
- Impact: Helps models generalize across different voice pitches and tonal variations.
- Implementation: Often uses phase vocoder techniques or frequency domain manipulation.
- Consideration: Moderate shifts (±2 semitones) are common to maintain naturalness.
Frequency Masking
- Process: Mask out certain frequency bands in the spectrogram.
- Example: In a speech spectrogram, mask out the frequency band 1000-2000 Hz.
- Impact: Improves model robustness to partial occlusions or missing frequency information.
- Implementation: Applied on the mel-spectrogram or MFCC features.
- Consideration: Typically mask width is a random value up to 27% of total mel frequency bands.
3. Noise Injection Techniques
These techniques add various types of noise to the audio:
Adding Background Noise
- Process: Mix in ambient sounds or noise to the clean audio.
- Example: Add cafe background noise to a clean speech recording.
- Impact: Improves model performance in noisy real-world environments.
- Implementation: Combine clean audio with noise at various Signal-to-Noise Ratios (SNR).
- Consideration: Use a diverse noise dataset (e.g., DEMAND, MUSAN) for better generalization.
Simulating Room Acoustics
- Process: Apply reverberation and echo effects to simulate different acoustic environments.
- Example: Add room reverberation to a dry voice recording to simulate a large hall.
- Impact: Helps models adapt to various acoustic settings (small rooms, large halls, outdoors).
- Implementation: Convolve the audio with room impulse responses (RIRs).
- Consideration: Use a variety of RIRs to simulate diverse environments.
Inserting Music or Speech Overlays
- Process: Mix in music or overlapping speech to the primary audio.
- Example: Add low-volume background music to a podcast recording.
- Impact: Improves model robustness in scenarios with multiple audio sources.
- Implementation: Combine primary audio with music/speech at various mixing ratios.
- Consideration: Ensure the primary audio remains intelligible after mixing.
4. Advanced Techniques
These are more sophisticated augmentation methods:
SpecAugment
- Process: Apply augmentation directly on the spectrogram representation of audio.
- Example: Apply time warping, frequency masking, and time masking on speech spectrograms.
- Impact: Significantly improves ASR performance, especially on limited data.
- Implementation: Manipulate the time-frequency representation of audio.
- Consideration: Originally proposed for ASR but effective for various audio tasks.
Voice Conversion
- Process: Change speaker characteristics while preserving linguistic content.
- Example: Convert a male voice to a female voice, or change accent/speaking style.
- Impact: Enhances model generalization across different speakers and speaking styles.
- Implementation: Often uses advanced techniques like GANs or VAEs.
- Consideration: Requires careful implementation to maintain speech naturalness and intelligibility.
Data Augmentation Tools
Several tools and libraries are available for implementing data augmentation in machine learning projects:
1. Albumentations
- A fast and flexible library for image augmentations
- Supports a wide range of transformations and easy integration with deep learning frameworks
2. imgaug
- A comprehensive library for image augmentation in machine learning and computer vision
- Offers a wide variety of augmentation techniques and easy-to-use interfaces
3. nlpaug
- A library for textual data augmentation in natural language processing
- Provides various augmentation methods at the character, word, and sentence levels
4. TensorFlow Data Augmentation
- Built-in data augmentation functionalities in TensorFlow and Keras
- Seamless integration with TensorFlow models and pipelines
5. PyTorch Transforms
- Data augmentation utilities provided by PyTorch
- Easily customizable and can be integrated into data loading pipelines
6. AugLy
- A data augmentation library by Facebook AI
- Supports augmentations for images, video, audio, and text
7. AutoAugment
- An automated data augmentation method developed by Google
- Uses reinforcement learning to find optimal augmentation policies
These tools provide developers and researchers with powerful options for implementing data augmentation in their machine-learning workflows, catering to various data types and project requirements.
Conclusion
Data augmentation is a crucial technique in modern machine learning, enhancing model performance and generalization. By artificially expanding datasets, it addresses challenges of data scarcity and overfitting. As AI continues to evolve, effective data augmentation will remain essential for developing robust, high-performing models.
FAQ's
1. How does data augmentation differ from data generation?
Data augmentation modifies existing data, while data generation creates entirely new synthetic data. Augmentation preserves original labels and characteristics, whereas generation can produce novel samples.
2. Can data augmentation introduce bias into the model?
Yes, if not carefully implemented. Inappropriate augmentation techniques or overuse can introduce unintended biases. It's crucial to validate augmented data and its impact on model performance.
3. Is data augmentation always beneficial for machine learning models?
Not always. Its effectiveness depends on the specific problem, dataset, and implementation. It's important to test and validate the impact of augmentation on your particular use case.


Ajay Patel
Hi, I am an AI engineer with 3.5 years of experience passionate about building intelligent systems that solve real-world problems through cutting-edge technology and innovative solutions.




